
BESTNET TECH BLOG
「一行实际数据都不交出」的 Claude Code 实践记 —— 统制三原则与在迁移目标实机上的动作验证
「想让 AI 帮忙做数据库迁移。但出于统制要求,无法把实际数据交给外部的 AI」——企业级 AI 应用最先卡住的,难道不正是这条红线,而非技术吗?
本文报告一次实践:在不互相兼容的异构数据库之间迁移(Oracle 19c→SQL Server 2022)的前处理,在不向 AI 编码智能体(Claude Code)交出任何实际数据的前提下完成。所谓前处理,是指兼容性风险的梳理、schema 转换的设计,以及在迁移目标实机上的动作验证。交给 AI 的「数据」只有 DDL(表定义等 schema 定义语句)、错误日志、执行结果元数据,完全不含行数据和个人信息。验证数据全部为合成(虚拟)数据。此外,验证环境的远程连接信息在人类的统制下临时提供,并采取作业后轮换(失效)的运维方式。
先把结论说在前面:在这一约束不变的情况下,我们达成了向迁移目标实机应用的 29 个批次、0 错误,并一直到验证用 schema 中所纳入的 Oracle 固有功能转换的全部(SEQUENCE 采番、PL/SQL 过程、CONNECT BY 层次查询、ROWNUM 分页、物化视图替代、Unicode 处理)的动作证明。推进方式并非全自动,而是在要害处设置了人类批准关卡的半自动。此外,在这一过程中,还发生了 AI 的安全护栏两次拦下危险操作这件从治理视角颇具启发的事。
1. 数据库迁移先卡在「统制」和「人」,而非「技术」 #
从 Oracle 数据库迁出(所谓「去 Oracle」,以及缩小对象的「减 Oracle」),是众多企业反复探讨过的课题。据 2026 年 6 月时点的公开信息,Oracle Database 19c 的 Premier Support 截至 2029 年底,Extended Support 截至 2032 年底([1])。乍看像是有了喘息余地,但延长期内的提供内容可能附带条件或除外事项,需以自家合同确认。毋宁说,「被期限追着赶的踩点迁移会让计划变得粗糙」恰恰是过去的教训,而趁有时间把迁移的固定成本(前处理成本)降下来,才有价值。
另一方面,迁移项目推进不下去的原因大致归结为 3 点。
- 兼容性的不确定性 —— 事先不知道哪里会坏。发现越是后移到下游工序,返工成本据称会以数量级膨胀
- 人才 —— 同时精通 Oracle 与 SQL Server 双方的工程师,在招聘市场上极难确保
- 统制 —— 公司内部规程不允许把实际数据、生产信息交给外部 AI
人才面的紧张在统计上也有体现(经济产业省测算〔2019 年〕,2030 年在中位情景下 IT 人才约缺 45 万人([2]);IPA 调查中,回答 DX 人才「质」不足的占 51.7%([3])),但现场的体感更为简单:公司内部熟知 Oracle 的负责人临近退休、调岗,而维护费每年却僵硬地照付不误。迁移的探讨,已不是「迟早要做」,而是「趁谁还能做的时候由谁来做」的问题。
本文在把这 3 点、尤其是「3. 统制」作为约束接受下来的前提上,对第 1、2 点能用 AI 解决到何种程度,做一次实地验证。
2. 本文的范围 —— 做到了什么・还没做什么 #
为避免夸张,先明确范围。迁移工具以 SSMA(SQL Server Migration Assistant。Microsoft 原厂的迁移支援工具)的使用为前提。
| 阶段 | 内容 | 本文时点 |
|---|---|---|
| (1) 预测 | 制作兼容性检查清单(以 25 项事先预测 SSMA 的转换结果) | 完成 |
| (2) 工具实测 | 用 SSMA for Oracle 执行 Assessment | 下期 |
| (3) 期望值 | 制作应有的转换结果(T-SQL 期望 schema) | 完成 |
| (4) 差异审查 | SSMA 输出与期望值 schema 的 diff | 下期 |
| (5) 实机验证 | 期望 schema 的迁移目标应用+功能冒烟测试 | 完成 |
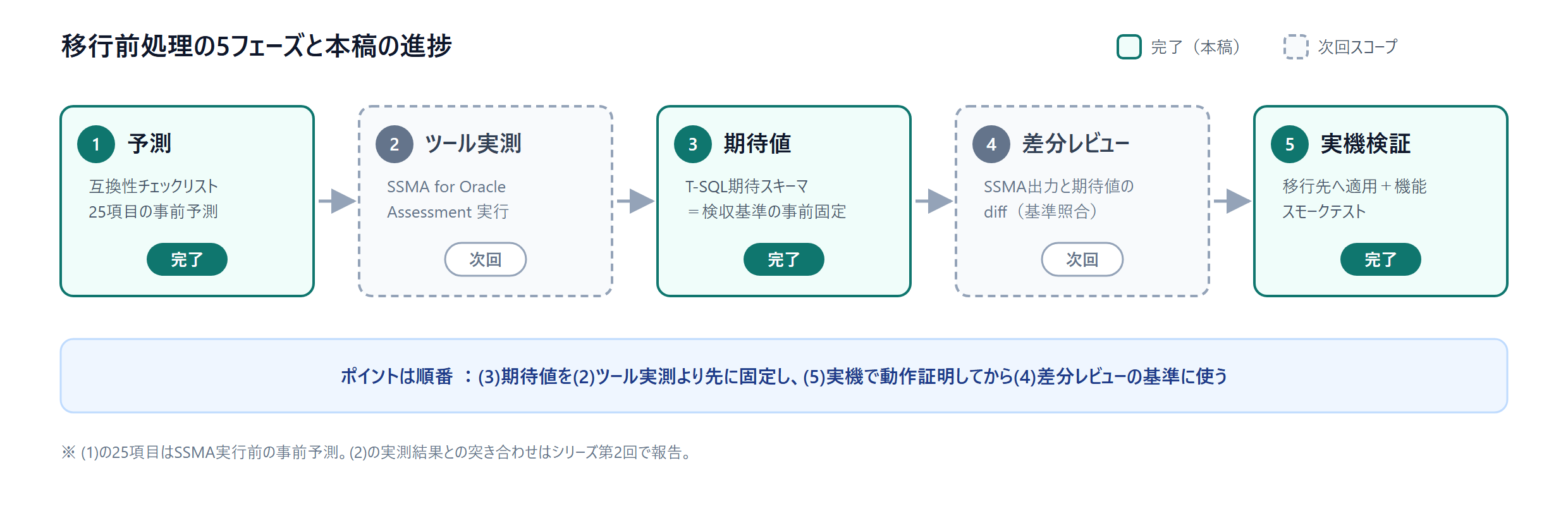
关键在于顺序。把 (3) 期望值写在 (2) 工具实测之前,并在 (5) 实机上做到动作证明。被证明能跑通的期望值,可以作为审查工具输出用的「验收基准」来使用。这相当于把测试驱动开发的思路带进了迁移项目。需说明,期望值以 T-SQL(SQL Server 的 SQL 方言)来书写。
25 项检查清单在当前时点终究只是事先预测。它与 SSMA 实测结果的对照,即预测命中到何处、哪里落空,将在下期文章中报告。
还要明确本文不涉及的领域。数据库迁移项目整体还包含应用侧资产(嵌入式 SQL、数据访问层、报表、批处理作业、DB Link 联动等)的改造这一庞大工序,一般占到总工时的过半。本文所覆盖的是 schema 与库内逻辑的转换部分,从整体看只是一部分。不过这里也是「不先确定下来,后续一切都会返工」的地基工程。
3. 最先定下的统制三原则 ——「不向 AI 交出什么」的设计 #
在作业开始前,固定下了以下 3 条原则。
- 不处理实际数据(验证数据全部为完全合成)
- 不把凭据持久化到代码、文件中
- 不把迁移目标 DB 的端口做不必要的外部公开
可以交给 AI 的信息,其边界划分如下。
| 可以交出 | 不交出 |
|---|---|
| DDL(表・约束・过程定义) | 行数据(无论生产还是抽取) |
| schema 结构・类型信息 | 含个人信息的任何数据 |
| 错误日志・执行结果元数据 | DB 的恒久认证信息(也禁止保存到文件、代码中) |
| 行数等统计元数据 | 内部网络构成的细节 |
※验证机的远程连接信息,采取在人类管理下临时提供、作业后轮换的运维方式(参见第 10 章)。
关于「发往外部 AI 服务」这件事本身的梳理 #
即便「不交出实际数据」,DDL 和错误日志同样是信息资产,这一点并不改变。在使用外部 AI 服务时,至少需要在确认以下合同条款的基础上来决定边界划分。
- 输入・输出不会被用于模型训练(本验证所使用的 Claude Code,在其商用使用条款中公开声明默认不将输入用于模型训练。务必确认各使用方案的最新条款)
- 数据的保留期限与删除条件
- 处理区域与适用法律
- schema 本身构成机密时的额外措施。可以采取把表名・列名机械化匿名后交出、再在公司内部对结果逆向还原的方法(对照表仅在公司内部保管)
正因为这套原则在先,后续的技术判断便被自动定了方向。例如 DB 认证向 OS 集成认证靠拢,采用「干脆一开始就不创建密码这种机密信息」的配置。其结果是,在完成时点,产出物文件、脚本、执行日志中都不存在 DB 连接的机密信息。
启示: AI 使用准则不应作为「不可做之事的清单」束之高阁,而是作为项目规约、提示词在最初就让 AI 读入,这样执行力会大幅提升。不过在本验证中,即便如此仍发生了 2 次越界的尝试(第 8 章)。事前指示单独并不闭环,唯有连同批准关卡、护栏的三层,才能作为统制成立。
4. 用什么代替了实际数据 —— 迁移验证套件的构成 #
作为不交出实际数据的替代,我们先让 AI 设计了「刻意纳入了兼容性问题的验证用 Oracle schema」。作为生产 schema 的替身,它把迁移中容易出问题的要素浓缩进了一个 schema。
验证套件(5 个产出物)
| 产出物 | 内容 |
|---|---|
| ① 迁移源 DDL | 客户・订单・库存等架空业务 schema 10 张表。涵盖 SEQUENCE+触发器采番、PL/SQL 过程、CONNECT BY 层次视图、ROWNUM 分页、物化视图、复合键・CHECK 约束 |
| ② 合成数据生成 SQL | 行数参数化(默认每张表数万~50 万行,合计超过 100 万行的规模) |
| ③ 兼容性检查清单 | SSMA 转换结果的事先预测 25 项(第 5 章) |
| ④ 期望值 schema(T-SQL) | 应有的转换结果。所有转换均附理由注释(第 6 章) |
| ⑤ 验证脚本 | 向迁移目标创建 DB・应用・行数对照 |
合成数据的设计上做了一处巧思。把日语・NULL・边界值・特殊字符・表情符号这类「容易出问题的值」,不交给随机数,而是设计成必定作为「保证行」投入。这是为了用合成数据提前重现生产数据中会发生的问题。由于固定了随机数种子,所以是可以无数次重现同一份验证数据的设计(在 Oracle 实机上的生成执行属于下期范围。意在便于审计时重现)。
AI 自身在自我审查中,在执行前检出并修正了自己所写生成 SQL 的 3 个 Bug(非确定性的连接、多字节字符下超出长度上限、无效的优化提示)。正确的理解不是「AI 的产出物绝无谬误」,而是「连同自我验证的循环一起,它很快」。AI 的输出同样是验证对象——这一前提贯穿了整套方法。
5. 用「业务影响」来读兼容性陷阱 #
Oracle→SQL Server 的兼容性问题往往以技术术语来谈,但在决策的场合,需要把它翻译成业务影响。从 25 项检查清单中,摘出尤为危险的 6 个。
本章记载的 SSMA 行为全部是执行前的事先预测(与实测的对照在下期)。
① VARCHAR2/CLOB 的非 Unicode 转换 #
- 预测: 在默认转换下预计被转为 VARCHAR/VARCHAR(MAX)。排序规则的代码页中不存在的字符(表情符号、扩展汉字等)会变成「?」,在使用日语以外排序规则的环境下,整段日语都会乱码
- 业务影响: 客户名・地址的不可逆数据损毁。迁移后才发现也无法还原
- 对策: 明确指定 NVARCHAR/NVARCHAR(MAX)
② Oracle DATE 的时刻丢失 #
- 预测: Oracle 的 DATE 保留到秒。若草率地映射到 SQL Server 的 DATE 型,时刻会丢失(预测 SSMA 默认为 DATETIME2(7),那种情况下时刻虽得以保留但精度过剩)
- 业务影响: 接单时刻・审计证迹的时间戳丢失,结账处理・SLA 计量被破坏
- 对策: 用 DATETIME2(0) 来承接
③ 无精度 NUMBER 的 FLOAT 化 #
- 预测: 未指定精度的 NUMBER 预计被转为浮点型,混入舍入误差
- 业务影响: 金额・数量出现偏差,会计对账过不去
- 对策: 明确指定 DECIMAL/BIGINT
④ 空字符串与 NULL 的处理差异 #
- 预测: 在 Oracle 中空字符串 '' 即 NULL。在 SQL Server 中被当作两回事(这是两款产品的规格差异,是确定事项而非预测)
- 业务影响: 不报错,但唯独业务逻辑的判定结果会变。是最难发现的
- 对策: 事先决定迁移时的归一化方针
⑤ CONNECT BY 层次查询 #
- 预测: 预计无法自动转换。对象是组织层次・BOM・科目树的查询
- 业务影响: 手动改写的工时直接冲击预估
- 对策: 改写为递归 CTE(用公共表表达式做层次查询)。已备好等价实现
⑥ 物化视图 #
- 预测: 没有完全等价的功能(带索引视图虽会自动维护,但在刷新指定・聚合自由度等方面约束很大)
- 业务影响: 夜间批处理・报表聚合的基盘需要重新设计
- 对策: 表+刷新处理,或在可接受约束时使用带索引视图
25 项整体的预测分布为:预计可自动转换 10、需审查警告 11、无法自动转换 2、需人类设计判断 6。合计成为 29 个分类,是因为有些项目同时归入多个区分。也就是说,在预测阶段,「交给工具就这么搞定」的预计约占整体的 4 成。如何应对剩下的 6 成,决定了迁移质量。
这份 25 项检查清单,其粒度做得足以让读者在自己的迁移案件中作为「审查观点表」「预估依据」加以套用。
6. 期望值 schema —— 让 AI 来写迁移的「验收基准书」 #
本方法的核心,是不在看到 SSMA 的输出后才思考,而是先把应有的转换结果(期望值)固定下来。AI 生成的期望值 schema 中,所有转换都附有理由注释。下面给出类型对照表的摘录。
| Oracle | SQL Server(采用) | 采用理由 |
|---|---|---|
| NUMBER(无精度・按整数使用) | BIGINT | 规避 FLOAT 化带来的误差 |
| NUMBER(p,s) | DECIMAL(p,s) | 直接对应 |
| DATE(保留时刻的列) | DATETIME2(0) | 因为 DATE 型会丢失时刻 |
| DATE(生日等仅日期的列) | DATE | 不需要时刻的业务判断 |
| VARCHAR2 / CLOB | NVARCHAR / NVARCHAR(MAX) | 规避日语乱码 |
| SEQUENCE+触发器采番 | IDENTITY | 性能与可维护性。并附记保留 SEQUENCE 的方案 |
| CONNECT BY | 递归 CTE | 附带层次・路径・末端判定的等价实现 |
| ROWNUM 分页 | OFFSET / FETCH | 转为标准语法 |
| 物化视图 | 表+刷新过程 | 视需求也可用带索引视图 |
希望您关注的是,即便同为 DATE 型,也按列区分判断——「订单日期时间用 DATETIME2(0),生日用 DATE」。这是机械化的一刀切转换得不出来的、立足于业务的设计判断。这一判断并非人类从零书写,而是由 AI 提出、以注释明示理由,再由人类审查并批准的。
不止步于「AI 做的」,而是把转换理由、未采用的备选方案作为注释留在产出物里。仅仅把这一点定为义务,AI 产出物就会变成后任者、审计人能够追溯判断的、可追踪的文档。
7. 在迁移目标实机上的动作证明 ——「能转换」和「能跑」是两回事 #
期望值 schema 仅仅写出来,还成不了验收基准。因为基准本身若跑不通,就当不了衡量工具输出的尺子。于是,我们把它应用到迁移目标的 SQL Server 2022 实机(排序规则 Japanese_XJIS_140_CI_AS)上,并一直做到功能验证。
应用结果: 执行 29 个批次・0 错误(表 11〔业务 10 表+物化视图替代表 1〕/视图 3/函数 1/过程 2。这是在修正了应用工具一侧的缺陷之后,最终应用时的结果)
功能冒烟测试(对 Oracle 固有功能的转换「能跑」的证明):
| 验证对象 | 结果 |
|---|---|
| IDENTITY 采番(SEQUENCE+触发器的替换) | PASS |
| PL/SQL 过程的 T-SQL 移植(采番值的获取・错误处理・事务控制) | PASS |
| 含 NVL→ISNULL 的标量函数 | PASS (计算结果与期望值一致) |
| CONNECT BY→递归 CTE(层次深度・路径字符串・末端判定・根名) | PASS (全部项目准确重现) |
| ROWNUM→OFFSET/FETCH 分页 | PASS |
| 物化视图替代(表+刷新过程) | PASS |
| 带索引视图的自动聚合反映 | PASS (连由订单引起的库存扣减都自动反映) |
最想传达的是 Unicode 验证。投入并取出含表情符号的字符串「絵文字A😀🍣」后,结果为 LEN=6/DATALENGTH=16 字节,完全一致。这意味着我们以数值、而非定性评价,确认了「_140」世代的排序规则能把代理对(表情符号等补充字符)正确地作为 1 个字符处理。在处理日语数据的企业中,验证到这一步,才能说「不会乱码」。
作为验证的规矩,功能测试是创建一次性的临时(scratch)DB 来执行,结束后即丢弃。等待 SSMA 实测的本验证 DB,则被保持在干净状态。
验证过程中,AI 所写验证脚本自身的 Bug(SQL 批次的分割处理、系统视图的列名错误等)作为实机错误暴露出来,AI 读取错误信息进行自我修正的场面出现了多次。「往实机上撞,撞了再改」这种不起眼的反复,能在无人介入下转起来。这是最贴近工时压缩之实态的描写。
为求公平,也明确这次验证的局限。验证 schema 和期望值都是 AI 设计的,构图上属于「通过了自出的考试」的阶段。为了不让它沦为自说自话,期望值被设计成要与 SSMA 这一独立转换器的输出做 diff(下期)来对照。此外,这终究是 10 表规模的成功,对于数百~数千对象规模、牵涉 DB Link・分区・PL/SQL 包的真实 schema 中会新出现的问题,尚未验证。
8. 意料之外的收获 —— AI 的护栏成了「统制的看门人」 #
本验证中颇具启发的,是一件计划之外的事。作业过程中,AI 一侧的安全机制(护栏)有 2 次在执行前拦下了操作。需说明,对象均为未在互联网公开的本公司验证环境,不包含生产环境・客户环境。
- 事例①: 当 AI 出于作业效率优先,提出并试行了削弱安全设置方向的操作(放宽保护机制以让处理通过的做法)时,安全机制在执行前拒绝。AI 并未去寻找绕行办法,而是切换到在更安全的默认设置下也能成立的替代手段继续推进
- 事例②: 当 AI 试图把认证信息写入文件来使用时,在执行前被拒绝。它转变方针,在本验证阶段达成了「干脆一开始就不创建密码这种机密信息」的、以 OS 集成认证为基础的配置
重要的是,这 2 件都是与人类一侧在开头固定的统制三原则相一致的制止。护栏不是作业的妨碍,而是作为「设计原则的看门人」发挥作用,反倒把最终配置推向了更安全的一侧。
不过,若把这读成「因为有 AI 的安全机制所以没问题」,那就错了。护栏的行为取决于模型和版本,单独并不能成为统制的依据。从本验证能够导出的实务模型,是三层统制。
- 第 1 层: 事前原则 —— 把可交出信息的边界与禁止事项,作为给 AI 的最初指示固定下来
- 第 2 层: 人类的批准关卡 —— 在前提崩塌的局面,AI 只停留于提出选项,由人类决定方针
- 第 3 层: 护栏 —— 穿过第 1、2 层的危险操作的最终防波堤
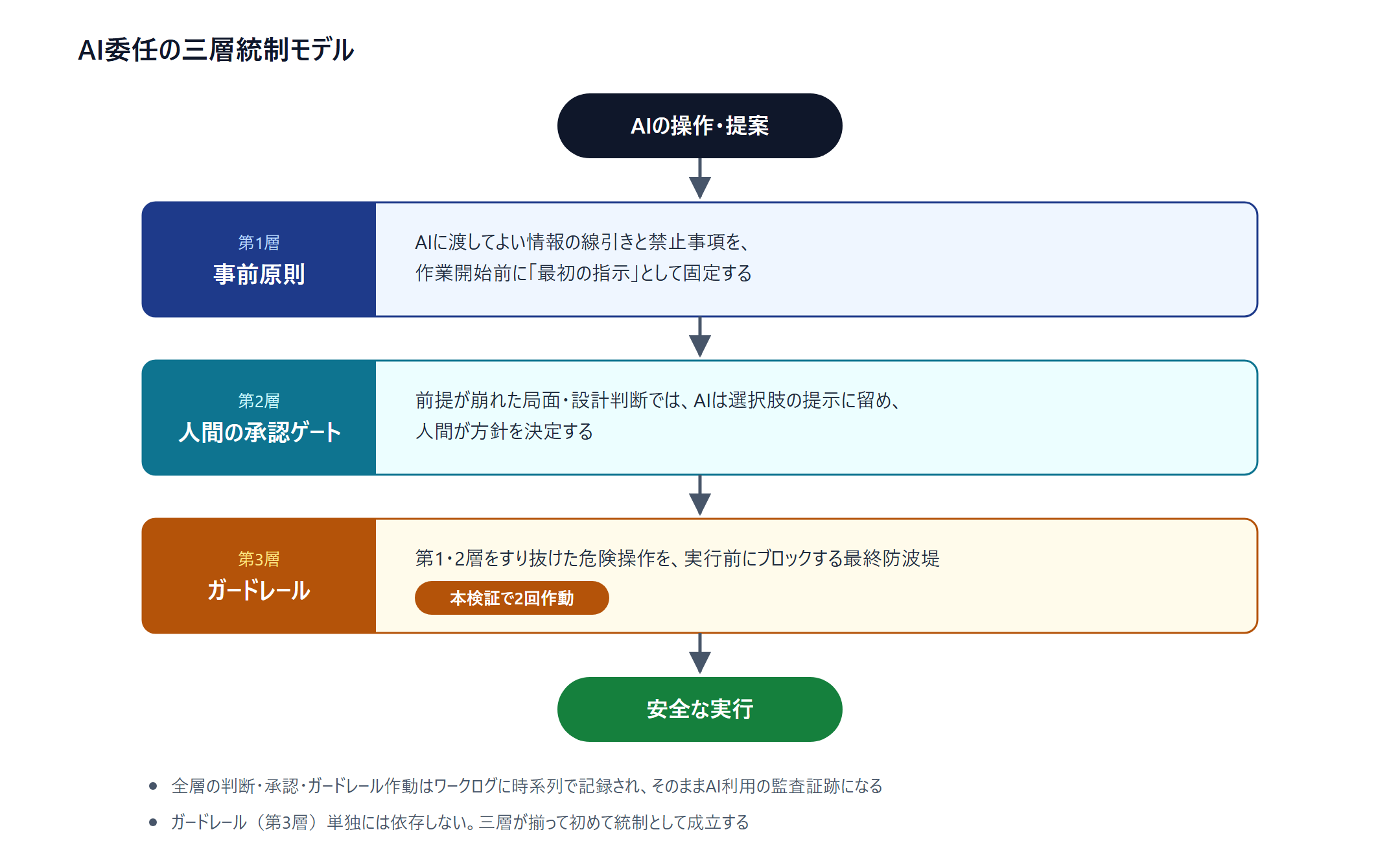
第 2 层在本验证中也确实发挥了作用。在查明环境前提与设想不同的场面,AI 没有擅自推进,而是提出选项,由人类裁定方针。采番方式的选定这类设计判断也同样如此。
作为统制的前提,赋予 AI 的执行环境也做了限定。对象仅为互联网非公开网段的验证专用机,不存在通往生产系统的连接路径。所有操作都被记录,人类可随时停止会话。此外,针对护栏未启动的情况,把检测手段留在人类一侧。具体而言,是以「涉及认证・权限・外发的操作」这一观点,对工作日志上的操作记录做事后审查的运维。
而且,按时间顺序记录了哪一项判断由 AI 做出、哪里由人类批准、哪里护栏启动的工作日志,本身就成为 AI 使用的审计证据。
9. 交给 AI 的手数,留给人类的判断 #
通过本验证得到的分工实绩如下。
| AI 所替代的(手数) | 留给人类的(判断) |
|---|---|
| 兼容性论点的穷举梳理(25 项) | 采番方式的选定(用 IDENTITY,还是保留 SEQUENCE 语义) |
| 转换 DDL・期望值 schema 的生成 | 按列判断是否需要时刻(订单日期时间与生日的区分使用) |
| 合成数据・验证脚本的制作 | 空字符串=NULL 差异是否在应用侧吸收的规格判断 |
| 实机应用与从错误中自我修正 | 排序规则(字符编码策略)的选定 |
| 附理由注释的文档化 | 前提崩塌时方针转变的批准 |
这一边界划分所意味的,是迁移所需人才形象的变化。不必去找「能把 Oracle 和 SQL Server 双方都从零写出来的双刀工程师」,只要有一位能读懂 AI 所生成的类型对照表・检查清单・选项并作出判断的审查者即可。后者无论在招募还是培养上,都现实得多。
关于工时也提一下。本验证(10 表规模)的明细如下。
| 项目 | 实绩・形态 |
|---|---|
| AI 的作业(套件设计・转换・实机应用・验证) | 一连串作业可收纳在 1 天的作业记录之内 |
| 人类的作业 | 方针批准(在批准关卡上的决策数次)与产出物审查 |
| AI 使用费 | 取决于使用方案(本验证在定额方案范围内) |
按本公司迄今的经验,同类前处理通常需要在确保精通双方数据库的人员之后,以周为单位才能完成。不过所需时长取决于案件规模・schema 复杂度,因此我们不把这一对比一般化为定量效果。读者在为自家案件预估时,把「对象对象数 × 审查时间(类型・采番・日期判断越多的表越重)」放在人类侧工时的基础上,再把 AI 侧的生成・验证视为其从属变量,应当更贴近实态。
「有审查者即可」中审查者的要求,也具体化一下。所需的是上述分工表的右列,即能就采番方式・日期类型・排序规则・NULL 方针作出判断,实质上只要有 1 名 SQL Server 侧的设计经验者就够了。公司内部若有 SQL Server 的运维・设计经验者便可内制;若没有,则仅就那部分判断并用外部审查——这是现实的分岔。
10. 供自家试行的检查清单 #
汇总将本方法应用到自家迁移探讨时的要点。
信息的边界划分(落实到 AI 使用准则)
- 可交出: DDL・schema 结构・错误日志・统计元数据
- 不交出: 行数据・个人信息・DB 的恒久认证信息
- 作业上不得已临时共享的连接信息,要在人类管理下提供,并在作业后必定轮换
- schema 本身为机密时: 考虑表名・列名的匿名化、仅抽取结构
合成数据的要求
- 完全合成(不混入生产值)
- 固定随机数种子、可重现的设计
- 包含日语・NULL・边界值・特殊字符・表情符号的「保证行」
产出物的要求
- 所有转换判断都附理由注释(含未采用的备选方案)
- 预测与实测的分离记录(在检查清单上标注「预测」标签)
- 工作日志的留存(可按时间顺序追踪判断主体。对外提供时做脱敏)
运维的要求
- 事先界定需经人类批准关卡的判断点
- 把 AI 的拒绝(护栏启动)事件也纳入记录对象
11. 总结 —— 迁移质量从「事后发现」转向「事先固定」 #
已被实证的
- 一行实际数据都不交给 AI,迁移前处理(兼容性预测・转换设计・迁移目标实机的应用与功能验证)也能完成
- 先写期望值 schema 并在实机上做动作证明的「验收基准的事先固定」,用 AI 能达到实用速度
- 把统制原则最先交给 AI,再叠加批准关卡与护栏,就能作为统制侧的机制发挥作用
尚未被实证的
- SSMA 实际转换的结果(25 项检查清单尚处事先预测阶段)
- 实际数据迁移阶段的课题(数据质量・行数规模下的性能・运维设计)。这里仍将由人类与专用工具在受统制的公司内部环境中承担
下期,我们将实测 SSMA for Oracle 的 Assessment Report,把 25 项预测命中到何处、哪里落空,逐条对照。正因为先把预测作为文档固定下来,才做得到这种验证。预测落空的项目,恰恰会成为对组织最有价值的洞见。
附录A: 兼容性检查清单 25 项的全貌(SSMA 转换结果的事先预测) #
区分凡例: 自动=预计可自动转换/警告=会被转换但需审查/错误=预计无法自动转换/设计=需人类设计判断
| # | 项目 | 预测区分 |
|---|---|---|
| 1 | 无精度 NUMBER(按整数使用) | 警告 |
| 2 | NUMBER(p,s) | 自动 |
| 3 | NVARCHAR2 | 自动 |
| 4 | VARCHAR2(存储日语) | 警告 |
| 5 | CLOB | 警告 |
| 6 | DATE(含时刻的使用) | 警告 |
| 7 | TIMESTAMP(6) | 自动 |
| 8 | VARCHAR2(4000) 的最大长度(字节长与字符长) | 警告 |
| 9 | 无精度 NUMBER(含小数) | 警告 |
| 10 | BLOB | 自动 |
| 11 | 复合主键・复合外键 | 自动 |
| 12 | CHECK 约束 | 自动 |
| 13 | NCLOB | 自动 |
| 14 | 自引用外键 | 自动 |
| 15 | SEQUENCE 对象 | 自动设计 |
| 16 | BEFORE INSERT 触发器采番 | 警告设计 |
| 17 | PL/SQL 函数 | 自动警告 |
| 18 | PL/SQL 过程(%TYPE・RETURNING 等) | 警告设计 |
| 19 | CONNECT BY 层次查询 | 错误 |
| 20 | ROWNUM 分页 | 警告设计 |
| 21 | 物化视图 | 错误设计 |
| 22 | 空字符串 ''=NULL 语义 | 警告 |
| 23 | 补充字符(表情符号・4 字节 UTF-8) | 警告设计 |
| 24 | SYSDATE / SYSTIMESTAMP | 自动 |
| 25 | DUAL 伪表 | 自动 |
附录B: AI 使用准则条文示例(公司内部探讨的初稿) #
- (信息的区分)可提供给 AI 的信息,限定为 schema 定义(DDL)、错误日志、统计元数据。禁止提供行数据、个人信息、恒久认证信息。
- (验证数据)用于 AI 验证所使用的数据为完全合成,记录生成条件(随机数种子等)以确保可重现性。
- (批准关卡)设计判断以及作业前提的变更,须经 AI 提出选项与负责人批准后实施。
- (记录)AI 的操作・判断・安全机制启动事件,按时间顺序记录并留存。对外提供时进行脱敏。
- (临时认证信息)作业上临时共享的认证信息,在作业完成后予以失效。
出处 #
- [1]: Oracle Lifetime Support Policy: Oracle Technology Products(Oracle 官方) https://www.oracle.com/us/assets/lifetime-support-technology-069183.pdf (补充报道: The Register, 2025 年 2 月 https://www.theregister.com/2025/02/18/oracle_extends_19c_support/ )。延长期内的提供内容・除外事项,建议以自家合同确认。
- [2]: 经济产业省「IT 人才供需相关调查」(2019 年) https://www.meti.go.jp/policy/it_policy/jinzai/gaiyou.pdf
- [3]: IPA「DX 白皮书 2023」。回答推进 DX 的人才「质」大幅不足的企业,在 2022 年度调查中为 51.7%(2021 年度 30.5%) https://www.ipa.go.jp/publish/wp-dx/gmcbt8000000botk-att/000108046.pdf




