
BESTNET TECH BLOG
"वास्तविक डेटा की एक भी पंक्ति साझा किए बिना" — Claude Code प्रैक्टिस रिपोर्ट: नियंत्रण के 3 सिद्धांत और लक्ष्य परिवेश की वास्तविक मशीन पर परिचालन सत्यापन
"मैं चाहता हूँ कि AI DB माइग्रेशन में मदद करे। लेकिन नियंत्रण की दृष्टि से, वास्तविक डेटा को बाहरी AI को सौंपना संभव नहीं है" — एंटरप्राइज़ में AI के उपयोग की पहली रुकावट तकनीक नहीं, बल्कि यही रेखा होती है, है ना?
इस लेख में, असंगत भिन्न-प्रकार के DB के बीच माइग्रेशन (Oracle 19c→SQL Server 2022) की प्रीप्रोसेसिंग को, AI कोडिंग एजेंट (Claude Code) को वास्तविक डेटा बिल्कुल भी साझा किए बिना अंजाम देने की प्रैक्टिस की रिपोर्ट दी गई है। प्रीप्रोसेसिंग से तात्पर्य है संगतता-जोखिमों की पहचान, स्कीमा रूपांतरण का डिज़ाइन, और लक्ष्य परिवेश की वास्तविक मशीन पर परिचालन सत्यापन। AI को साझा किया गया "डेटा" केवल DDL (टेबल परिभाषा आदि की स्कीमा परिभाषा-कथन), एरर लॉग और निष्पादन-परिणाम मेटाडेटा था — इसमें पंक्ति-डेटा या व्यक्तिगत जानकारी बिल्कुल शामिल नहीं है। सत्यापन डेटा पूरी तरह सिंथेटिक (डमी) डेटा है। साथ ही, सत्यापन परिवेश से रिमोट कनेक्शन की जानकारी मानवीय नियंत्रण के अधीन अस्थायी रूप से दी जाती है और कार्य के बाद उसे रोटेट (निष्क्रिय) करने की प्रणाली अपनाई गई है।
निष्कर्ष पहले कहें तो, इसी बंधन को कायम रखते हुए, लक्ष्य परिवेश की वास्तविक मशीन पर अनुप्रयोग के 29 बैच, 0 एरर, और सत्यापन-स्कीमा में शामिल सभी Oracle-विशिष्ट फ़ीचर के रूपांतरण (SEQUENCE नंबरिंग, PL/SQL प्रक्रिया, CONNECT BY पदानुक्रम क्वेरी, ROWNUM पेजिंग, मटेरियलाइज़्ड व्यू का विकल्प, Unicode प्रोसेसिंग) के परिचालन-प्रमाण तक पहुँचा जा सका। आगे बढ़ने का तरीका पूर्णतः स्वचालित नहीं, बल्कि मुख्य बिंदुओं पर मानवीय अनुमोदन-गेट रखकर अर्ध-स्वचालित है। इसके अलावा, इस प्रक्रिया में, AI के सुरक्षा गार्डरेल ने खतरनाक ऑपरेशन को निष्पादन से पहले 2 बार ब्लॉक किया — जो गवर्नेंस की दृष्टि से बहुत संकेतपूर्ण घटना भी थी।
1. DB माइग्रेशन "तकनीक" से पहले "नियंत्रण" और "मानव" पर रुक जाता है #
Oracle डेटाबेस से माइग्रेशन (तथाकथित "Oracle से पलायन", दायरे को सीमित करने वाला "Oracle में कटौती") कई कंपनियों में बार-बार विचार किया जाने वाला विषय रहा है। जून 2026 तक की सार्वजनिक जानकारी के अनुसार, Oracle Database 19c का Premier Support 2029 के अंत तक और Extended Support 2032 के अंत तक बताया गया है ([1])। एक नज़र में लगता है कि मोहलत मिल गई, लेकिन विस्तारित अवधि के दौरान दी जाने वाली सामग्री में शर्तें और अपवाद हो सकते हैं, इसलिए अपने अनुबंध में पुष्टि करना आवश्यक है। बल्कि "समय-सीमा से पीछा करते हुए की गई जल्दबाज़ी माइग्रेशन की योजना लचर हो जाती है" — यही अतीत का सबक है, और समय रहते माइग्रेशन की स्थिर लागत (प्रीप्रोसेसिंग लागत) को कम कर रखने में मूल्य है।
दूसरी ओर, माइग्रेशन प्रोजेक्ट के आगे न बढ़ने के कारण मोटे तौर पर 3 में सिमट जाते हैं।
- संगतता की अनिश्चितता — कहाँ टूटेगा यह पहले से पता नहीं चलता। पता लगना जितना बाद के चरण में खिसकता है, उतना ही पुनः-कार्य की लागत कई गुना बढ़ती बताई जाती है
- मानव-संसाधन — Oracle और SQL Server दोनों में निपुण इंजीनियर को भर्ती-बाज़ार में हासिल करना बेहद कठिन है
- नियंत्रण — वास्तविक डेटा / प्रोडक्शन जानकारी को बाहरी AI को सौंपना कंपनी के नियमों के तहत संभव नहीं है
मानव-संसाधन का यह दबाव आँकड़ों में भी दिखता है (अर्थव्यवस्था, व्यापार एवं उद्योग मंत्रालय के अनुमान〔2019〕में 2030 में IT मानव-संसाधन की मध्यम परिदृश्य में लगभग 4,50,000 की कमी ([2]), IPA सर्वेक्षण में DX मानव-संसाधन की "गुणवत्ता" की कमी का उत्तर 51.7% ([3])), लेकिन ज़मीनी अनुभव और भी सीधा है। कंपनी के Oracle को पूरी तरह जानने वाले प्रभारी की सेवानिवृत्ति/स्थानांतरण नज़दीक आ रहा है, जबकि रखरखाव-शुल्क हर साल जड़ता से निकलता रहता है। माइग्रेशन पर विचार "कभी न कभी करेंगे" नहीं, बल्कि "जब तक कोई कर सकता है, तब तक कौन करेगा" का प्रश्न बन गया है।
यह लेख इन तीनों में से, खासकर "3. नियंत्रण" को एक बंधन के रूप में स्वीकार करते हुए, 1 और 2 को AI से कहाँ तक हल किया जा सकता है, इसका व्यावहारिक सत्यापन है।
2. इस लेख का दायरा — जो हो सका, जो अभी नहीं किया #
अतिशयोक्ति से बचने के लिए, सबसे पहले दायरा स्पष्ट करते हैं। माइग्रेशन टूल के रूप में SSMA (SQL Server Migration Assistant। Microsoft का अपना माइग्रेशन सहायता टूल) के उपयोग को पूर्वधारणा माना गया है।
| चरण | सामग्री | इस लेख के समय |
|---|---|---|
| (1) पूर्वानुमान | संगतता चेकलिस्ट बनाना (SSMA के रूपांतरण-परिणाम का 25 मदों में पूर्वानुमान) | पूर्ण |
| (2) टूल वास्तविक-माप | SSMA for Oracle द्वारा Assessment निष्पादन | अगली बार |
| (3) अपेक्षित मान | आदर्श रूपांतरण-परिणाम (T-SQL अपेक्षित स्कीमा) बनाना | पूर्ण |
| (4) अंतर समीक्षा | SSMA आउटपुट और अपेक्षित-मान स्कीमा का diff | अगली बार |
| (5) वास्तविक-मशीन सत्यापन | अपेक्षित स्कीमा का लक्ष्य परिवेश पर अनुप्रयोग + फ़ीचर स्मोक टेस्ट | पूर्ण |
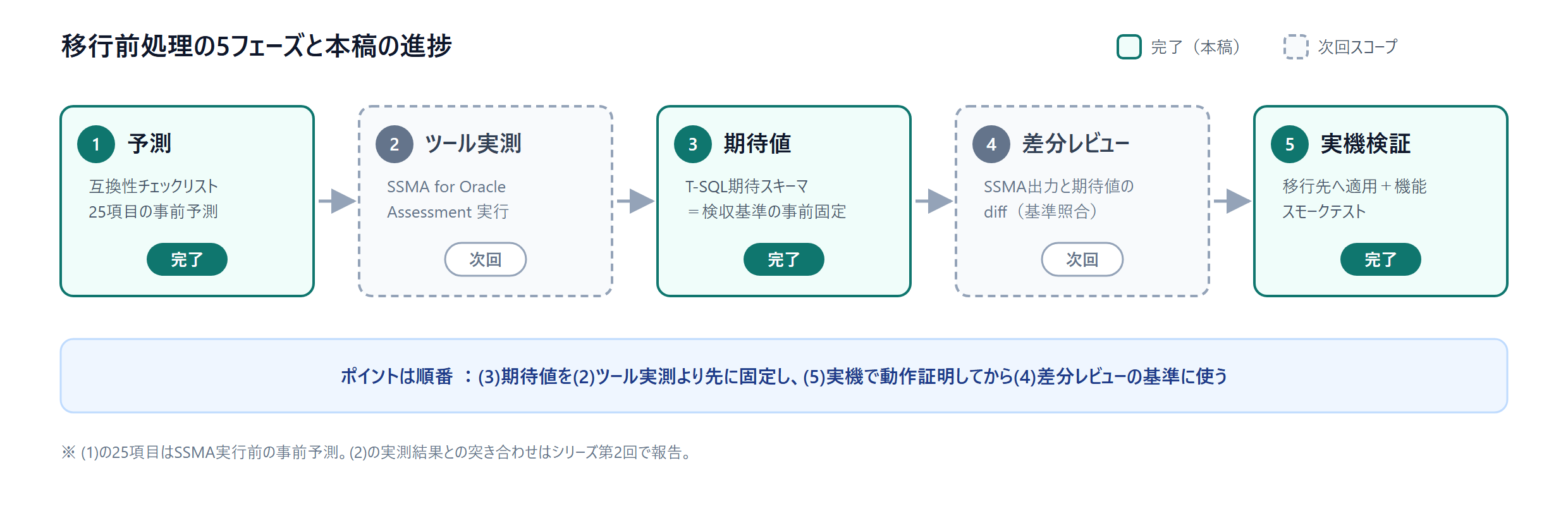
मुख्य बात क्रम है। (3) अपेक्षित मान को (2) टूल वास्तविक-माप से पहले लिखें, और (5) वास्तविक मशीन पर परिचालन-प्रमाण तक कर रखें। जिस अपेक्षित मान का चलना सिद्ध हो चुका है, उसे टूल के आउटपुट की समीक्षा के लिए "स्वीकृति-मानदंड" के रूप में इस्तेमाल किया जा सकता है। यह टेस्ट-ड्रिवन डेवलपमेंट की सोच को माइग्रेशन प्रोजेक्ट में लाने का रूप है। ध्यान दें, अपेक्षित मान को T-SQL (SQL Server की SQL बोली) में लिखा जाता है।
25 मदों की चेकलिस्ट इस समय केवल पूर्व-अनुमान भर है। SSMA के वास्तविक-माप परिणाम से मिलान, यानी पूर्वानुमान कहाँ तक सही और कहाँ गलत होता है, इसकी रिपोर्ट अगले लेख में देंगे।
एक और बात, इस लेख में जो क्षेत्र शामिल नहीं हैं उन्हें भी स्पष्ट कर दें। समूचे DB माइग्रेशन प्रोजेक्ट में, एप्लिकेशन-पक्ष की परिसंपत्तियों (एम्बेडेड SQL, डेटा-एक्सेस लेयर, रिपोर्ट, बैच जॉब, DB लिंक संयोजन आदि) के सुधार का एक बड़ा चरण होता है, जो आमतौर पर कुल कार्य-घंटों के आधे से अधिक होता है। यह लेख जो कवर करता है वह स्कीमा और DB-आंतरिक लॉजिक का रूपांतरण-भाग है, जो पूरे से देखें तो एक हिस्सा है। हालाँकि यही वह बुनियादी कार्य भी है जो "सबसे पहले तय न हो तो आगे का सब कुछ पुनः-कार्य बन जाता है"।
3. सबसे पहले तय किए गए नियंत्रण के 3 सिद्धांत — "AI को क्या न सौंपें" का डिज़ाइन #
कार्य शुरू करने से पहले, निम्नलिखित 3 सिद्धांत स्थिर कर दिए।
- वास्तविक डेटा नहीं संभालेंगे (सत्यापन डेटा पूरी तरह से पूर्णतः सिंथेटिक)
- क्रेडेंशियल को कोड/फ़ाइल में स्थायी रूप से नहीं रखेंगे
- लक्ष्य DB के पोर्ट को अनावश्यक रूप से बाहर सार्वजनिक नहीं करेंगे
AI को साझा की जा सकने वाली जानकारी की सीमा-रेखा इस प्रकार है।
| साझा किया जा सकता है | साझा नहीं करेंगे |
|---|---|
| DDL (टेबल, कंस्ट्रेंट, प्रोसीजर परिभाषा) | पंक्ति-डेटा (प्रोडक्शन हो या निष्कर्षित) |
| स्कीमा संरचना / टाइप जानकारी | व्यक्तिगत जानकारी वाला कोई भी डेटा |
| एरर लॉग / निष्पादन-परिणाम मेटाडेटा | DB की स्थायी प्रमाणीकरण जानकारी (फ़ाइल/कोड में सहेजना भी निषिद्ध) |
| संख्या आदि सांख्यिकीय मेटाडेटा | आंतरिक नेटवर्क संरचना का विवरण |
※ सत्यापन मशीन से रिमोट कनेक्शन की जानकारी को मानवीय प्रबंधन के अधीन अस्थायी रूप से दिया गया और कार्य के बाद रोटेट करने की प्रणाली अपनाई गई (अध्याय 10 देखें)।
"बाहरी AI सेवा को भेजना" — इसी बात का विश्लेषण #
भले ही "वास्तविक डेटा न सौंपें", फिर भी DDL और एरर लॉग भी सूचना-परिसंपत्ति ही हैं, इसमें कोई बदलाव नहीं। बाहरी AI सेवा के उपयोग के समय, कम से कम निम्नलिखित अनुबंध-शर्तों की पुष्टि करके सीमा-रेखा तय करना आवश्यक है।
- इनपुट/आउटपुट का मॉडल के प्रशिक्षण में उपयोग न हो (इस सत्यापन में प्रयुक्त Claude Code के बारे में, वाणिज्यिक-उपयोग शर्तों में यह घोषित है कि इनपुट को डिफ़ॉल्ट रूप से मॉडल प्रशिक्षण में उपयोग नहीं किया जाता। प्रत्येक उपयोग-प्लान की नवीनतम शर्तों की पुष्टि अनिवार्य है)
- डेटा की धारण-अवधि और विलोपन-शर्तें
- प्रोसेसिंग रीजन और लागू कानून
- स्कीमा स्वयं गोपनीय होने की स्थिति में अतिरिक्त उपाय। टेबल-नाम/कॉलम-नाम को यांत्रिक रूप से अनामीकृत करके सौंपा जा सकता है और परिणाम को कंपनी के भीतर वापस-रूपांतरित किया जा सकता है (मैपिंग-तालिका केवल कंपनी के भीतर रखें)
यह सिद्धांत पहले होने से, आगे के तकनीकी निर्णय स्वतः दिशा पा गए। उदाहरण के लिए DB प्रमाणीकरण को OS-एकीकृत प्रमाणीकरण की ओर झुकाकर, "पासवर्ड नामक गुप्त जानकारी को मूलतः बनाते ही नहीं" वाली संरचना अपनाई है। नतीजतन, पूर्ण होने के समय परिणाम-फ़ाइल, स्क्रिप्ट या निष्पादन-लॉग में से किसी में भी DB कनेक्शन की गुप्त जानकारी मौजूद नहीं है।
संकेत: AI उपयोग दिशानिर्देश को "न करने योग्य बातों की सूची" के रूप में ताक पर रखने के बजाय, प्रोजेक्ट-नियम / प्रॉम्प्ट के रूप में AI को सबसे पहले पढ़ाने पर प्रवर्तन-शक्ति बहुत बढ़ जाती है। हालाँकि इस सत्यापन में, फिर भी विचलन के प्रयास 2 बार हुए (अध्याय 8)। पूर्व-निर्देश अकेले में पूर्ण नहीं होता; अनुमोदन-गेट और गार्डरेल सहित तीन परतों में ही नियंत्रण के रूप में स्थापित होता है।
4. वास्तविक डेटा के बदले क्या साझा किया — माइग्रेशन सत्यापन किट की संरचना #
वास्तविक डेटा न साझा करने के बदले, AI से सबसे पहले "संगतता-समस्याओं को जानबूझकर शामिल किया गया सत्यापन-हेतु Oracle स्कीमा" डिज़ाइन कराया। प्रोडक्शन स्कीमा के प्रतिनिधि के रूप में, माइग्रेशन में समस्या बनने वाले तत्वों को एक ही स्कीमा में संघनित किया गया है।
सत्यापन किट (5 परिणाम-वस्तुएँ)
| परिणाम-वस्तु | सामग्री |
|---|---|
| ① स्रोत DDL | ग्राहक, ऑर्डर, इन्वेंट्री आदि की काल्पनिक व्यापार-स्कीमा के 10 टेबल। SEQUENCE + ट्रिगर नंबरिंग, PL/SQL प्रोसीजर, CONNECT BY पदानुक्रम व्यू, ROWNUM पेजिंग, मटेरियलाइज़्ड व्यू, संयुक्त-कुंजी / CHECK कंस्ट्रेंट को समाहित करता है |
| ② सिंथेटिक डेटा जनरेशन SQL | पंक्ति-संख्या को पैरामीटरीकृत (डिफ़ॉल्ट में प्रति टेबल कुछ दसियों हज़ार~5 लाख पंक्तियाँ, कुल मिलाकर 10 लाख पंक्तियों से अधिक का पैमाना) |
| ③ संगतता चेकलिस्ट | SSMA रूपांतरण-परिणाम का 25 मदों में पूर्व-अनुमान (अध्याय 5) |
| ④ अपेक्षित-मान स्कीमा (T-SQL) | आदर्श रूपांतरण-परिणाम। सभी रूपांतरणों में कारण-टिप्पणी सहित (अध्याय 6) |
| ⑤ सत्यापन स्क्रिप्ट | लक्ष्य पर DB निर्माण/अनुप्रयोग/संख्या-मिलान |
सिंथेटिक डेटा के डिज़ाइन में एक तरकीब लगाई है। जापानी, NULL, सीमा-मान, विशेष वर्ण, इमोजी जैसे "समस्या पैदा करने वाले मान" को यादृच्छिकता के भरोसे न छोड़कर "गारंटीड पंक्ति" के रूप में अवश्य डालने का डिज़ाइन बनाया। प्रोडक्शन डेटा में होने वाली समस्या को सिंथेटिक डेटा में पहले ही पुनः-उत्पन्न करने के लिए। यादृच्छिक सीड स्थिर होने के कारण, समान सत्यापन डेटा को कितनी भी बार पुनः-उत्पन्न किया जा सकता है (Oracle वास्तविक मशीन पर जनरेशन का निष्पादन अगली बार के दायरे में। ऑडिट के समय पुनरुत्पादन का उद्देश्य है)।
AI ने स्वयं सेल्फ-रिव्यू में, अपने बनाए जनरेशन SQL के 3 बग (अनिर्धारणात्मक जॉइन, मल्टीबाइट वर्ण में लंबाई-सीमा का उल्लंघन, अमान्य ऑप्टिमाइज़ेशन हिंट) को निष्पादन से पहले पकड़कर ठीक किया है। "AI के परिणाम अचूक होते हैं" नहीं, बल्कि "स्व-सत्यापन की लूप सहित तेज़ हैं" — यही सही समझ है। AI का आउटपुट भी सत्यापन का विषय है — यह पूर्वधारणा पूरी पद्धति में व्याप्त है।
5. संगतता के नुकसान को "व्यापार-प्रभाव" से पढ़ना #
Oracle→SQL Server की संगतता-समस्याएँ अक्सर तकनीकी शब्दों में बताई जाती हैं, लेकिन निर्णय-स्थल पर उन्हें व्यापार-प्रभाव में अनुवादित करना आवश्यक है। चेकलिस्ट के 25 मदों में से, खास तौर पर खतरनाक 6 का चयन प्रस्तुत है।
इस अध्याय में वर्णित SSMA का व्यवहार पूरी तरह निष्पादन-पूर्व पूर्व-अनुमान है (वास्तविक-माप से मिलान अगली बार)।
① VARCHAR2/CLOB का गैर-Unicode रूपांतरण #
- पूर्वानुमान: डिफ़ॉल्ट रूपांतरण में VARCHAR/VARCHAR(MAX) में बदलने की संभावना। कोलेशन के कोड-पेज में अनुपस्थित वर्ण (इमोजी, विस्तारित कांजी आदि) "?" में बदल जाएँगे, और जापानी-इतर कोलेशन वाले परिवेश में समूचा जापानी ही गड़बड़ा जाएगा
- व्यापार-प्रभाव: ग्राहक-नाम/पते की अपरिवर्तनीय डेटा-क्षति। माइग्रेशन के बाद पता चलने पर भी मूल स्थिति में नहीं लौटाया जा सकता
- उपाय: NVARCHAR/NVARCHAR(MAX) स्पष्ट रूप से निर्दिष्ट करें
② Oracle DATE का समय खो जाना #
- पूर्वानुमान: Oracle का DATE सेकंड तक धारण करता है। SQL Server के DATE टाइप में लापरवाही से मैप करने पर समय गायब हो जाता है (SSMA का डिफ़ॉल्ट DATETIME2(7) होने का अनुमान है, उस स्थिति में समय तो धारण होता है पर परिशुद्धता अत्यधिक होती है)
- व्यापार-प्रभाव: ऑर्डर-समय / ऑडिट-ट्रेल का टाइमस्टैम्प गायब होकर, क्लोज़िंग प्रोसेस / SLA माप टूट जाता है
- उपाय: DATETIME2(0) में लें
③ परिशुद्धता-रहित NUMBER का FLOAT में बदलना #
- पूर्वानुमान: परिशुद्धता-निर्दिष्ट-रहित NUMBER के फ़्लोटिंग-पॉइंट टाइप में बदलने की संभावना, जिससे राउंडिंग-त्रुटि मिल जाती है
- व्यापार-प्रभाव: राशि/मात्रा खिसककर लेखांकन-मिलान पास नहीं होता
- उपाय: DECIMAL/BIGINT स्पष्ट रूप से निर्दिष्ट करें
④ खाली स्ट्रिंग और NULL के व्यवहार का अंतर #
- पूर्वानुमान: Oracle में खाली स्ट्रिंग '' NULL है। SQL Server में इसे अलग चीज़ के रूप में संभाला जाता है (यह दोनों उत्पादों के विनिर्देश का अंतर है और पूर्वानुमान नहीं, बल्कि निश्चित तथ्य है)
- व्यापार-प्रभाव: एरर तो नहीं आता पर व्यापार-लॉजिक का केवल निर्णय-परिणाम बदल जाता है। पकड़ना सबसे कठिन
- उपाय: माइग्रेशन के समय की सामान्यीकरण-नीति पहले से तय करें
⑤ CONNECT BY पदानुक्रम क्वेरी #
- पूर्वानुमान: स्वचालित रूपांतरण असंभव होने का अनुमान। संगठन-पदानुक्रम, BOM, खाता-वृक्ष की क्वेरी इसका लक्ष्य
- व्यापार-प्रभाव: मैनुअल पुनर्लेखन का कार्य-घंटा सीधे अनुमान पर चोट करता है
- उपाय: रिकर्सिव CTE (कॉमन टेबल एक्सप्रेशन द्वारा पदानुक्रम क्वेरी) में पुनर्लेखन। समतुल्य कार्यान्वयन तैयार रखा गया है
⑥ मटेरियलाइज़्ड व्यू #
- पूर्वानुमान: पूर्ण समतुल्य फ़ीचर नहीं है (इंडेक्स्ड व्यू स्वचालित रूप से अनुरक्षित होता है, पर रिफ़्रेश-निर्देश / एग्रीगेशन की स्वतंत्रता आदि की कड़ी सीमाएँ हैं)
- व्यापार-प्रभाव: रात्रिकालीन बैच / रिपोर्ट-एग्रीगेशन के आधार का पुनः-डिज़ाइन
- उपाय: टेबल + रिफ़्रेश प्रोसेस, या सीमाएँ स्वीकार्य होने पर इंडेक्स्ड व्यू
समस्त 25 मदों के पूर्वानुमान का विवरण: स्वचालित रूपांतरण की संभावना 10, समीक्षा-आवश्यक चेतावनी 11, स्वचालित रूपांतरण असंभव 2, मानवीय डिज़ाइन-निर्णय आवश्यक 6। कुल 29 वर्गीकरण इसलिए बनते हैं क्योंकि कुछ मद एक से अधिक वर्गों में आते हैं। यानी पूर्वानुमान के चरण में ही, "टूल पर छोड़कर वैसे ही काम चल जाने" की संभावना समूचे का लगभग 40% है। बाकी 60% के लिए कैसे तैयारी करें — यही माइग्रेशन की गुणवत्ता तय करता है।
यह 25-मद चेकलिस्ट, पाठक के माइग्रेशन प्रोजेक्ट में भी "समीक्षा-दृष्टिकोण तालिका" / "अनुमान-आधार" के रूप में पुनः-उपयोग योग्य ग्रैन्युलैरिटी में बनाई गई है।
6. अपेक्षित-मान स्कीमा — माइग्रेशन का "स्वीकृति-मानदंड दस्तावेज़" AI से लिखवाना #
इस पद्धति का मूल है — SSMA का आउटपुट देखकर सोचने के बजाय, आदर्श रूपांतरण-परिणाम (अपेक्षित मान) को पहले स्थिर करना। AI द्वारा जनरेट की गई अपेक्षित-मान स्कीमा में, सभी रूपांतरणों पर कारण-टिप्पणी लगी है। टाइप-मैपिंग तालिका का एक अंश प्रस्तुत है।
| Oracle | SQL Server (अपनाया गया) | अपनाने का कारण |
|---|---|---|
| NUMBER (परिशुद्धता-रहित, पूर्णांक उपयोग) | BIGINT | FLOAT में बदलने से होने वाली त्रुटि से बचाव |
| NUMBER(p,s) | DECIMAL(p,s) | जस का तस संगत |
| DATE (समय धारण करने वाला कॉलम) | DATETIME2(0) | DATE टाइप में समय गायब हो जाने के कारण |
| DATE (जन्मदिन आदि केवल-दिनांक कॉलम) | DATE | समय अनावश्यक होने का व्यापार-निर्णय |
| VARCHAR2 / CLOB | NVARCHAR / NVARCHAR(MAX) | जापानी के वर्ण-विकृति से बचाव |
| SEQUENCE + ट्रिगर नंबरिंग | IDENTITY | प्रदर्शन और रखरखाव-योग्यता। SEQUENCE बनाए रखने का प्रस्ताव भी साथ अंकित |
| CONNECT BY | रिकर्सिव CTE | पदानुक्रम/पथ/पत्ती-निर्णय का समतुल्य कार्यान्वयन सहित |
| ROWNUM पेजिंग | OFFSET / FETCH | मानक सिंटैक्स की ओर |
| मटेरियलाइज़्ड व्यू | टेबल + रिफ़्रेश प्रोसीजर | आवश्यकता के अनुसार इंडेक्स्ड व्यू भी |
जिस ओर ध्यान दिलाना चाहता हूँ वह यह है कि समान DATE टाइप में भी "ऑर्डर-दिनांक-समय DATETIME2(0), जन्मदिन DATE" — इस तरह कॉलम-स्तर पर निर्णय अलग किए गए हैं। यह यांत्रिक एकमुश्त रूपांतरण से नहीं निकलता; व्यापार को ध्यान में रखकर लिया गया डिज़ाइन-निर्णय है। यह निर्णय मानव ने शून्य से नहीं लिखा, बल्कि AI ने प्रस्तावित किया और टिप्पणी में कारण स्पष्ट किया, और मानव ने समीक्षा करके अनुमोदित किया।
"AI ने बना दिया" पर बात खत्म न करके, रूपांतरण का कारण और न अपनाए गए विकल्प को टिप्पणी के रूप में परिणाम-वस्तु में छोड़ें। बस इसे अनिवार्य कर देने भर से, AI के परिणाम उत्तराधिकारी/ऑडिटर द्वारा निर्णय का अनुसरण करने योग्य ट्रेसेबल दस्तावेज़ बन जाते हैं।
7. लक्ष्य परिवेश की वास्तविक मशीन पर परिचालन-प्रमाण — "रूपांतरण हो गया" और "चलता है" अलग बातें हैं #
अपेक्षित-मान स्कीमा, केवल लिख देने भर से स्वीकृति-मानदंड नहीं बनती। यदि मानदंड स्वयं ही न चले, तो वह टूल के आउटपुट को मापने का पैमाना नहीं बन सकता। इसलिए लक्ष्य के SQL Server 2022 वास्तविक मशीन (कोलेशन Japanese_XJIS_140_CI_AS) पर इसे लागू करके, फ़ीचर-सत्यापन तक किया।
अनुप्रयोग परिणाम: 29 बैच निष्पादित, 0 एरर (टेबल 11〔व्यापार 10 टेबल + मटेरियलाइज़्ड व्यू विकल्प टेबल 1〕/ व्यू 3 / फ़ंक्शन 1 / प्रोसीजर 2। अनुप्रयोग-टूल-पक्ष के दोष को ठीक करने के बाद के अंतिम अनुप्रयोग का परिणाम है)
फ़ीचर स्मोक टेस्ट (Oracle-विशिष्ट फ़ीचर का रूपांतरण "चलता है" इसका प्रमाण):
| सत्यापन-विषय | परिणाम |
|---|---|
| IDENTITY नंबरिंग (SEQUENCE + ट्रिगर का प्रतिस्थापन) | PASS |
| PL/SQL प्रोसीजर का T-SQL में पोर्ट (नंबरिंग-मान प्राप्ति, एरर हैंडलिंग, ट्रांज़ैक्शन नियंत्रण) | PASS |
| NVL→ISNULL सहित स्केलर फ़ंक्शन | PASS (गणना-परिणाम अपेक्षित मान से मेल खाता है) |
| CONNECT BY→रिकर्सिव CTE (पदानुक्रम की गहराई, पथ-स्ट्रिंग, पत्ती-निर्णय, रूट-नाम) | PASS (सभी मद सटीक रूप से पुनरुत्पादित) |
| ROWNUM→OFFSET/FETCH पेजिंग | PASS |
| मटेरियलाइज़्ड व्यू विकल्प (टेबल + रिफ़्रेश प्रोसीजर) | PASS |
| इंडेक्स्ड व्यू का स्वचालित एग्रीगेशन प्रतिबिंबन | PASS (ऑर्डर द्वारा इन्वेंट्री घटाव तक स्वचालित प्रतिबिंबित) |
जो सबसे ज़्यादा बताना चाहता हूँ वह Unicode सत्यापन है। इमोजी सहित स्ट्रिंग "絵文字A😀🍣" को डालकर प्राप्त करने पर, LEN=6 / DATALENGTH=16 बाइट के साथ पूर्ण मेल हुआ। "_140" पीढ़ी का कोलेशन सरोगेट पेयर (इमोजी आदि पूरक वर्ण) को सही ढंग से 1 वर्ण के रूप में संभालता है — इसे गुणात्मक मूल्यांकन से नहीं, बल्कि संख्या से पुष्टि किया गया। जापानी डेटा संभालने वाले एंटरप्राइज़ में, यहाँ तक सत्यापन करने के बाद ही "वर्ण-विकृति नहीं होती" कहा जा सकता है।
सत्यापन के तरीके के रूप में, फ़ीचर-टेस्ट को एक डिस्पोज़ेबल स्क्रैच DB बनाकर निष्पादित किया गया और समाप्ति के बाद उसे नष्ट कर दिया गया। SSMA वास्तविक-माप का इंतज़ार करने वाला यह सत्यापन-DB साफ़-सुथरा बना हुआ है।
सत्यापन के दौरान, AI द्वारा लिखी सत्यापन-स्क्रिप्ट के अपने बग (SQL बैच का विभाजन-प्रोसेसिंग, या सिस्टम-व्यू के कॉलम-नाम की गलती आदि) वास्तविक-मशीन एरर के रूप में सामने आए, और AI ने एरर-संदेश पढ़कर स्वयं को सुधारा — ऐसे दृश्य कई बार आए। "वास्तविक मशीन से टकराकर ठीक करना" — यह सामान्य-सा पुनरावृत्ति बिना मानवीय हाथ के चलना। कार्य-घंटा संकुचन की वास्तविकता का यही सबसे निकट चित्रण है।
निष्पक्षता के लिए, इस सत्यापन की सीमाएँ भी स्पष्ट करते हैं। सत्यापन-स्कीमा और अपेक्षित-मान दोनों AI ने डिज़ाइन किए हैं, और संरचना की दृष्टि से यह "अपने बनाए परीक्षण में पास हुआ" वाला चरण है। यह आत्म-संतुष्ट होकर न रह जाए, इसलिए अपेक्षित-मान को SSMA नामक एक स्वतंत्र रूपांतरक के आउटपुट से diff (अगली बार) द्वारा मिलान करने का डिज़ाइन है। साथ ही, यह मात्र 10-टेबल पैमाने की सफलता है; सैकड़ों~हज़ारों ऑब्जेक्ट के पैमाने, DB लिंक/पार्टीशन/PL/SQL पैकेज में उलझी वास्तविक स्कीमा में नए सिरे से प्रकट होने वाली समस्याएँ असत्यापित हैं।
8. अप्रत्याशित उपलब्धि — AI का गार्डरेल "नियंत्रण का प्रहरी" बन गया #
इस सत्यापन में जो संकेतपूर्ण था, वह एक अनियोजित घटना थी। कार्य के दौरान, AI-पक्ष के सुरक्षा गार्डरेल ने 2 बार, ऑपरेशन को निष्पादन से पहले ब्लॉक किया। ध्यान दें, लक्ष्य दोनों ही बार इंटरनेट पर अप्रकाशित कंपनी का सत्यापन परिवेश था; प्रोडक्शन परिवेश / ग्राहक परिवेश शामिल नहीं।
- उदाहरण ①: जब AI ने कार्य-दक्षता को प्राथमिकता देकर, सुरक्षा-सेटिंग को कमज़ोर करने की दिशा का ऑपरेशन (सुरक्षा-तंत्र को शिथिल करके प्रोसेस पास कराने वाला तरीका) प्रस्तावित/प्रयास किया, तब निष्पादन से पहले गार्डरेल ने अस्वीकार किया। AI ने चकमा देने का रास्ता ढूँढने के बजाय, अधिक सुरक्षित डिफ़ॉल्ट सेटिंग में ही चल जाने वाले वैकल्पिक तरीके पर स्विच करके जारी रखा
- उदाहरण ②: जब AI ने प्रमाणीकरण-जानकारी को फ़ाइल में लिखकर उपयोग करने का प्रयास किया, तब निष्पादन से पहले अस्वीकार हुआ। नीति बदलकर, इस सत्यापन-चरण में "पासवर्ड नामक गुप्त जानकारी को मूलतः बनाते ही नहीं" वाली OS-एकीकृत प्रमाणीकरण आधारित संरचना तक पहुँचा
महत्वपूर्ण यह है कि दोनों ही मानव-पक्ष द्वारा शुरुआत में स्थिर किए गए नियंत्रण के 3 सिद्धांतों से मेल खाती रोक थी। गार्डरेल कार्य की बाधा नहीं, बल्कि "डिज़ाइन-सिद्धांत के प्रहरी" के रूप में काम कर गया और अंतिम संरचना को उल्टा सुरक्षित-पक्ष की ओर धकेल दिया।
हालाँकि, इसे "AI का सुरक्षा-तंत्र है इसलिए चिंता नहीं" पढ़ना गलत है। गार्डरेल का व्यवहार मॉडल/संस्करण पर निर्भर करता है और अकेले में नियंत्रण का आधार नहीं बनता। इस सत्यापन से जो व्यावहारिक मॉडल निकाला जा सकता है वह त्रि-स्तरीय नियंत्रण है।
- परत 1: पूर्व-सिद्धांत — साझा की जा सकने वाली जानकारी की सीमा-रेखा और निषिद्ध बातों को, AI को पहले निर्देश के रूप में स्थिर करें
- परत 2: मानवीय अनुमोदन-गेट — पूर्वधारणा टूटने वाले मोड़ पर AI विकल्पों की प्रस्तुति तक सीमित रहे और मानव नीति तय करे
- परत 3: गार्डरेल — परत 1·2 को फिसलकर निकले खतरनाक ऑपरेशन का अंतिम बाँध
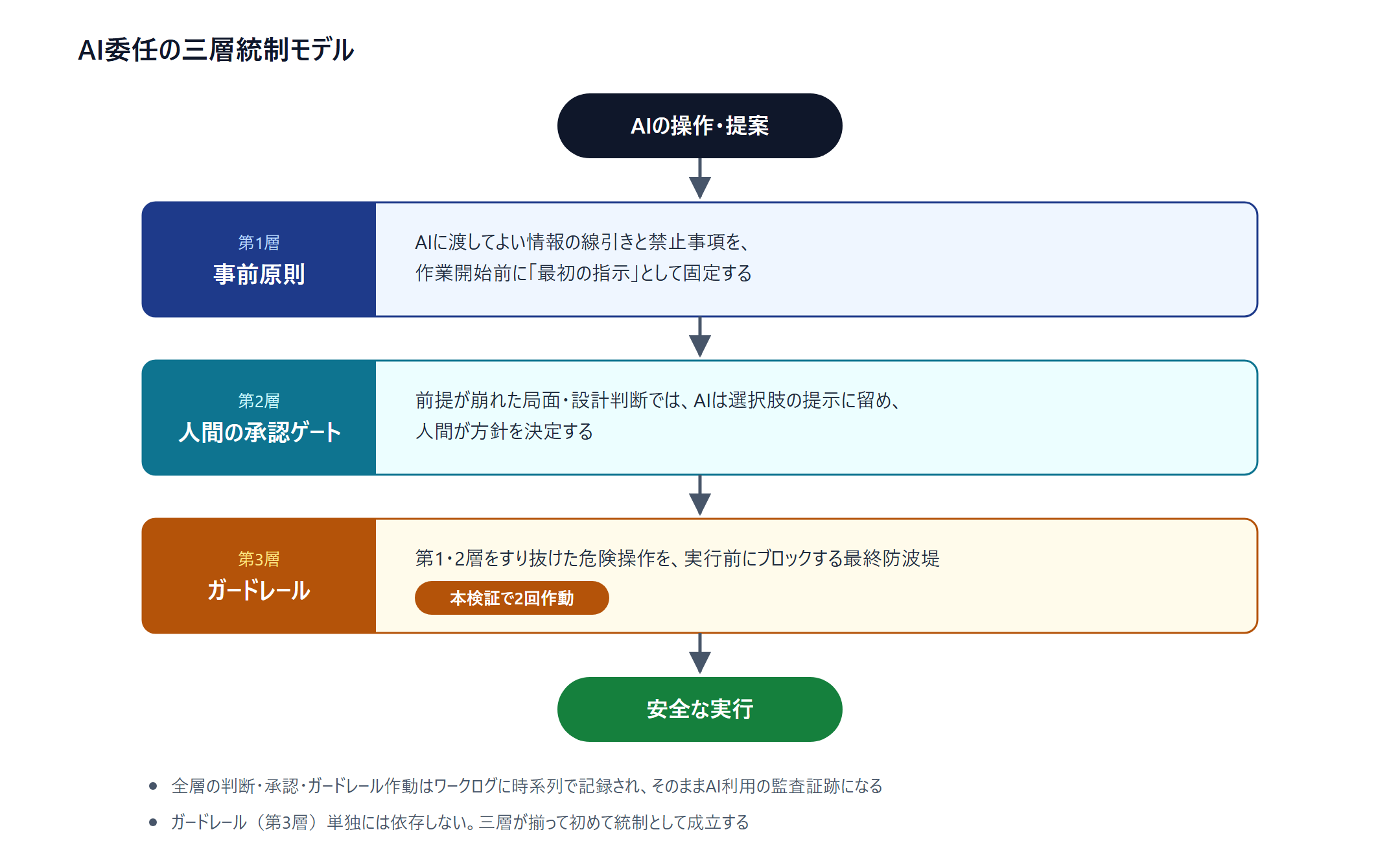
परत 2 इस सत्यापन में भी वास्तव में काम कर रही है। जहाँ परिवेश की पूर्वधारणा अनुमान से भिन्न पाई गई, वहाँ AI ने स्वेच्छाचार से आगे न बढ़कर विकल्प प्रस्तुत किए और मानव ने नीति का निर्णय लिया। नंबरिंग-विधि के चयन जैसे डिज़ाइन-निर्णय में भी यही।
नियंत्रण की पूर्वधारणा के रूप में, AI को दिया गया निष्पादन-परिवेश भी सीमित है। लक्ष्य केवल इंटरनेट पर अप्रकाशित सेगमेंट की सत्यापन-समर्पित मशीन है, और प्रोडक्शन-सिस्टम तक कोई कनेक्शन-मार्ग नहीं। सभी ऑपरेशन रिकॉर्ड होते हैं और मानव कभी भी सेशन रोक सकता है। इसके अलावा, गार्डरेल के सक्रिय न होने की स्थिति के लिए पहचान-साधन मानव-पक्ष के पास रखे जाते हैं। ठोस रूप में, वर्क-लॉग के ऑपरेशन-रिकॉर्ड को "प्रमाणीकरण/अधिकार/बाहरी-प्रेषण से जुड़े ऑपरेशन" के दृष्टिकोण से उत्तरवर्ती समीक्षा करने की प्रणाली है।
और, कौन-सा निर्णय AI ने लिया, कहाँ मानव ने अनुमोदित किया, और कहाँ गार्डरेल सक्रिय हुआ — इसे कालक्रमानुसार रिकॉर्ड करने वाला वर्क-लॉग, सीधे AI-उपयोग का ऑडिट-ट्रेल बन जाता है।
9. AI को सौंपे गए हाथ-काम, मानव के पास बचे निर्णय #
इस सत्यापन के दौरान भूमिका-विभाजन का परिणाम इस प्रकार है।
| AI ने जो प्रतिस्थापित किया (हाथ-काम) | मानव के पास जो बचा (निर्णय) |
|---|---|
| संगतता-बिंदुओं की समावेशी पहचान (25 मद) | नंबरिंग-विधि का चयन (IDENTITY, या SEQUENCE सिमेंटिक्स बनाए रखना) |
| रूपांतरित DDL / अपेक्षित-मान स्कीमा का जनरेशन | कॉलम-स्तर पर समय की आवश्यकता (ऑर्डर-दिनांक-समय और जन्मदिन का भेद) |
| सिंथेटिक डेटा / सत्यापन-स्क्रिप्ट का निर्माण | खाली-स्ट्रिंग=NULL अंतर को एप्लिकेशन-पक्ष में सोखने का विनिर्देश-निर्णय |
| वास्तविक-मशीन अनुप्रयोग और एरर से स्व-सुधार | कोलेशन (वर्ण-कोड रणनीति) का चयन |
| कारण-टिप्पणी सहित दस्तावेज़ीकरण | पूर्वधारणा टूटने पर नीति-परिवर्तन का अनुमोदन |
यह सीमा-रेखा जो दर्शाती है, वह माइग्रेशन के लिए आवश्यक मानव-छवि का परिवर्तन है। "Oracle और SQL Server दोनों को शून्य से लिख सकने वाला उभय-निपुण इंजीनियर" ढूँढने के बजाय, AI द्वारा जनरेट की गई टाइप-मैपिंग तालिका / चेकलिस्ट / विकल्पों को पढ़कर निर्णय ले सकने वाला समीक्षक हो तो काम चल जाता है। बाद वाला, खरीद और प्रशिक्षण दोनों दृष्टि से कहीं अधिक व्यावहारिक है।
कार्य-घंटे का भी ज़िक्र कर दें। इस सत्यापन (10-टेबल पैमाना) का विवरण इस प्रकार है।
| मद | परिणाम/स्वरूप |
|---|---|
| AI का कार्य (किट डिज़ाइन, रूपांतरण, वास्तविक-मशीन अनुप्रयोग, सत्यापन) | एक श्रृंखला का कार्य 1 दिन के कार्य-रिकॉर्ड में समा जाता है |
| मानव का कार्य | नीति-अनुमोदन (अनुमोदन-गेट पर निर्णय कुछ बार) और परिणाम-वस्तु की समीक्षा |
| AI उपयोग-शुल्क | उपयोग-प्लान पर निर्भर (यह सत्यापन निश्चित-शुल्क प्लान के दायरे में) |
हमारे अब तक के अनुभव में, इसी प्रकार की प्रीप्रोसेसिंग के लिए दोनों DB में निपुण कर्मी को हासिल करके सप्ताह-इकाई में समय लगना आम बात थी। हालाँकि आवश्यक समय प्रोजेक्ट-पैमाने / स्कीमा-जटिलता पर निर्भर करता है, इसलिए इस तुलना को मात्रात्मक प्रभाव के रूप में सामान्यीकृत करने से हम बचते हैं। पाठक जब अपने प्रोजेक्ट का अनुमान लगाएँ, तो "लक्ष्य ऑब्जेक्ट-संख्या × समीक्षा-समय (टाइप/नंबरिंग/दिनांक का निर्णय आवश्यक टेबल जितने अधिक, उतना भारी)" को मानव-पक्ष कार्य-घंटे का आधार रखें, और AI-पक्ष के जनरेशन/सत्यापन को उसका आश्रित चर मानें — यह वास्तविकता के अधिक निकट होगा।
"समीक्षक हो तो काम चल जाता है" के समीक्षक-की-आवश्यकता को भी ठोस कर दें। आवश्यक यह है कि उपरोक्त भूमिका-विभाजन तालिका का दायाँ स्तंभ, यानी नंबरिंग-विधि / दिनांक-टाइप / कोलेशन / NULL-नीति का निर्णय ले सके — व्यावहारिक रूप से SQL Server-पक्ष का डिज़ाइन-अनुभवी 1 व्यक्ति हो तो पर्याप्त है। यदि कंपनी में SQL Server के परिचालन/डिज़ाइन का अनुभवी हो तो आंतरिक रूप से संभव, न हो तो केवल उस निर्णय-भाग के लिए बाहरी समीक्षा साथ लें — यह व्यावहारिक विकल्प-बिंदु है।
10. अपनी कंपनी में आज़माने के लिए चेकलिस्ट #
इस पद्धति को अपनी कंपनी के माइग्रेशन-विचार पर लागू करने की स्थिति के मुख्य बिंदुओं का सारांश।
जानकारी की सीमा-रेखा (AI उपयोग दिशानिर्देश में उतारना)
- साझा कर सकते हैं: DDL / स्कीमा संरचना / एरर लॉग / सांख्यिकीय मेटाडेटा
- साझा नहीं करेंगे: पंक्ति-डेटा / व्यक्तिगत जानकारी / DB की स्थायी प्रमाणीकरण जानकारी
- कार्य के लिए मजबूरीवश अस्थायी साझा की जाने वाली कनेक्शन-जानकारी को मानवीय प्रबंधन के अधीन दें और कार्य के बाद अवश्य रोटेट करें
- स्कीमा स्वयं गोपनीय होने पर: टेबल-नाम/कॉलम-नाम का अनामीकरण, केवल संरचना का निष्कर्षण विचार करें
सिंथेटिक डेटा की आवश्यकताएँ
- पूर्णतः सिंथेटिक (प्रोडक्शन-मान का मिश्रण नहीं)
- यादृच्छिक सीड स्थिर रखकर पुनरुत्पादन-योग्य डिज़ाइन
- जापानी, NULL, सीमा-मान, विशेष वर्ण, इमोजी की "गारंटीड पंक्ति" शामिल हो
परिणाम-वस्तु की आवश्यकताएँ
- सभी रूपांतरण-निर्णयों पर कारण-टिप्पणी (न अपनाए गए विकल्प भी)
- पूर्वानुमान और वास्तविक-माप का पृथक रिकॉर्ड (चेकलिस्ट पर "पूर्वानुमान" लेबल)
- वर्क-लॉग का संरक्षण (निर्णय-कर्ता कालक्रमानुसार पता लगे। बाहर प्रदान करते समय सैनिटाइज़ करें)
परिचालन की आवश्यकताएँ
- मानवीय अनुमोदन-गेट से गुज़रने वाले निर्णय-बिंदुओं की पूर्व-परिभाषा
- AI के अस्वीकार (गार्डरेल सक्रियण) की घटना भी रिकॉर्ड के दायरे में
11. निष्कर्ष — माइग्रेशन की गुणवत्ता "बाद में ढूँढने" से "पहले स्थिर करने" की ओर #
जो सिद्ध हुआ
- वास्तविक डेटा की एक भी पंक्ति AI को साझा किए बिना, माइग्रेशन प्रीप्रोसेसिंग (संगतता-पूर्वानुमान, रूपांतरण-डिज़ाइन, लक्ष्य की वास्तविक मशीन पर अनुप्रयोग और फ़ीचर-सत्यापन) पूरी की जा सकती है
- अपेक्षित-मान स्कीमा को पहले लिखकर वास्तविक मशीन पर परिचालन-प्रमाण करने वाला "स्वीकृति-मानदंड का पूर्व-स्थिरीकरण", AI के साथ व्यावहारिक गति पर आ जाता है
- नियंत्रण-सिद्धांतों को सबसे पहले AI को देकर, अनुमोदन-गेट और गार्डरेल को परत-दर-परत रखें, तो नियंत्रण-पक्ष के तंत्र के रूप में काम करता है
जो अभी सिद्ध नहीं हुआ
- SSMA द्वारा वास्तविक रूपांतरण का परिणाम (25-मद चेकलिस्ट पूर्व-अनुमान के चरण में है)
- वास्तविक-डेटा माइग्रेशन चरण की चुनौतियाँ (डेटा-गुणवत्ता, संख्या-पैमाने पर प्रदर्शन, परिचालन-डिज़ाइन)। यह क्षेत्र आगे भी, नियंत्रित कंपनी-परिवेश में मानव और समर्पित टूल द्वारा संभाला जाने वाला है
अगली बार, SSMA for Oracle की Assessment Report का वास्तविक-माप करेंगे और 25 मदों का पूर्वानुमान कहाँ तक सही और कहाँ गलत निकला, इसे एक-एक करके मिलान करेंगे। पूर्वानुमान को पहले दस्तावेज़ के रूप में स्थिर करने के कारण ही यह सत्यापन संभव है। जिन मदों में पूर्वानुमान गलत निकला, वही संगठन के लिए सबसे मूल्यवान ज्ञान बनेंगे।
परिशिष्ट A: संगतता चेकलिस्ट के 25 मदों की समग्र तस्वीर (SSMA रूपांतरण-परिणाम का पूर्व-अनुमान) #
वर्ग की कुंजी: स्वचालित=स्वचालित रूपांतरण की संभावना / चेतावनी=रूपांतरित तो होता है पर समीक्षा-आवश्यक / एरर=स्वचालित रूपांतरण असंभव की संभावना / डिज़ाइन=मानवीय डिज़ाइन-निर्णय आवश्यक
| # | मद | पूर्वानुमान वर्ग |
|---|---|---|
| 1 | परिशुद्धता-रहित NUMBER (पूर्णांक उपयोग) | चेतावनी |
| 2 | NUMBER(p,s) | स्वचालित |
| 3 | NVARCHAR2 | स्वचालित |
| 4 | VARCHAR2 (जापानी संग्रहण) | चेतावनी |
| 5 | CLOB | चेतावनी |
| 6 | DATE (समय सहित उपयोग) | चेतावनी |
| 7 | TIMESTAMP(6) | स्वचालित |
| 8 | VARCHAR2(4000) की अधिकतम लंबाई (बाइट-लंबाई और वर्ण-लंबाई) | चेतावनी |
| 9 | परिशुद्धता-रहित NUMBER (दशमलव सहित) | चेतावनी |
| 10 | BLOB | स्वचालित |
| 11 | संयुक्त प्राथमिक-कुंजी / संयुक्त विदेशी-कुंजी | स्वचालित |
| 12 | CHECK कंस्ट्रेंट | स्वचालित |
| 13 | NCLOB | स्वचालित |
| 14 | स्व-संदर्भी विदेशी-कुंजी | स्वचालित |
| 15 | SEQUENCE ऑब्जेक्ट | स्वचालितडिज़ाइन |
| 16 | BEFORE INSERT ट्रिगर द्वारा नंबरिंग | चेतावनीडिज़ाइन |
| 17 | PL/SQL फ़ंक्शन | स्वचालितचेतावनी |
| 18 | PL/SQL प्रोसीजर (%TYPE, RETURNING आदि) | चेतावनीडिज़ाइन |
| 19 | CONNECT BY पदानुक्रम क्वेरी | एरर |
| 20 | ROWNUM पेजिंग | चेतावनीडिज़ाइन |
| 21 | मटेरियलाइज़्ड व्यू | एररडिज़ाइन |
| 22 | खाली स्ट्रिंग ''=NULL सिमेंटिक्स | चेतावनी |
| 23 | पूरक वर्ण (इमोजी, 4-बाइट UTF-8) | चेतावनीडिज़ाइन |
| 24 | SYSDATE / SYSTIMESTAMP | स्वचालित |
| 25 | DUAL छद्म-टेबल | स्वचालित |
परिशिष्ट B: AI उपयोग दिशानिर्देश के अनुच्छेद-उदाहरण (कंपनी-आंतरिक विचार का प्रारूप) #
- (जानकारी का वर्गीकरण) AI को प्रदान की जा सकने वाली जानकारी स्कीमा परिभाषा (DDL), एरर लॉग, सांख्यिकीय मेटाडेटा होगी। पंक्ति-डेटा, व्यक्तिगत जानकारी, स्थायी प्रमाणीकरण-जानकारी का प्रावधान निषिद्ध है।
- (सत्यापन डेटा) AI से सत्यापन में प्रयुक्त डेटा पूर्णतः सिंथेटिक होगा, और जनरेशन-शर्तें (यादृच्छिक सीड आदि) रिकॉर्ड करके पुनरुत्पादन-योग्यता सुनिश्चित की जाएगी।
- (अनुमोदन-गेट) डिज़ाइन-निर्णय और कार्य-पूर्वधारणा का परिवर्तन, AI द्वारा विकल्पों की प्रस्तुति और प्रभारी के अनुमोदन के बाद किया जाएगा।
- (रिकॉर्ड) AI के ऑपरेशन/निर्णय/सुरक्षा-तंत्र की सक्रियण-घटना को कालक्रमानुसार रिकॉर्ड और संरक्षित किया जाएगा। बाहर प्रदान करते समय सैनिटाइज़ किया जाएगा।
- (अस्थायी प्रमाणीकरण-जानकारी) कार्य के लिए अस्थायी रूप से साझा प्रमाणीकरण-जानकारी को कार्य पूर्ण होने के बाद निष्क्रिय किया जाएगा।
स्रोत #
- [1]: Oracle Lifetime Support Policy: Oracle Technology Products (Oracle आधिकारिक) https://www.oracle.com/us/assets/lifetime-support-technology-069183.pdf (पूरक रिपोर्टिंग: The Register, फ़रवरी 2025 https://www.theregister.com/2025/02/18/oracle_extends_19c_support/ )। विस्तारित अवधि के दौरान दी जाने वाली सामग्री/अपवादों की पुष्टि अपने अनुबंध में करने की अनुशंसा है।
- [2]: अर्थव्यवस्था, व्यापार एवं उद्योग मंत्रालय "IT मानव-संसाधन की माँग-आपूर्ति पर सर्वेक्षण" (2019) https://www.meti.go.jp/policy/it_policy/jinzai/gaiyou.pdf
- [3]: IPA "DX श्वेत-पत्र 2023"। DX को आगे बढ़ाने वाले मानव-संसाधन की "गुणवत्ता" अत्यधिक कमी का उत्तर देने वाली कंपनियाँ 2022 वित्तीय वर्ष के सर्वेक्षण में 51.7% (2021 वित्तीय वर्ष 30.5%) https://www.ipa.go.jp/publish/wp-dx/gmcbt8000000botk-att/000108046.pdf




