
BESTNET TECH BLOG
A "not a single row of real data handed over" Claude Code field record — three control principles and operation verification on the actual target machine
"We want to have AI help with the DB migration. But for control reasons, we cannot hand real data to an external AI." — Isn't this line, rather than technology, the first place where enterprise AI adoption stalls?
In this article, we report a hands-on case in which we carried out the preprocessing for a migration between incompatible heterogeneous DBs (Oracle 19c → SQL Server 2022) with an AI coding agent (Claude Code), without handing over any real data. Preprocessing refers to identifying compatibility risks, designing the schema conversion, and verifying operation on the actual target machine. The "data" handed to the AI was only DDL (schema-definition statements such as table definitions), error logs, and execution-result metadata — no row data or personal information whatsoever. All verification data is synthetic (dummy) data. Note that the remote connection information for the verification environment was provided temporarily under human control, and the operation is to rotate (invalidate) it after the work.
To state the conclusion first: under these very constraints, we reached 29 application batches to the actual target machine with zero errors, and demonstrated the operation of all the Oracle-specific feature conversions built into the verification schema (SEQUENCE numbering, PL/SQL procedures, CONNECT BY hierarchical queries, ROWNUM paging, materialized-view alternatives, Unicode handling). The approach is not fully automated but semi-automated, with human approval gates placed at key points. Also, in the process, there was an event rich with implications from a governance perspective: the AI's safety guardrail blocked dangerous operations twice.
1. DB Migration Stalls at "Control" and "People" Before "Technology" #
Migrating away from an Oracle database (the so-called "de-Oracle," or "reduce-Oracle" that narrows the targets) is a theme that has been repeatedly considered at many companies. According to information published as of June 2026, Premier Support for Oracle Database 19c is stated to run until the end of 2029, and Extended Support until the end of 2032 ([1]). At first glance this looks like a reprieve, but the offering during the extension period may have conditions and exclusions, so confirmation under your own contract is necessary. Rather, the lesson of the past is precisely that "a last-minute migration chased by a deadline makes for sloppy planning," and there is value in lowering the fixed cost of migration (the preprocessing cost) while there is still time.
On the other hand, the reasons a migration project does not progress roughly boil down to three.
- Uncertainty of compatibility — You cannot know in advance where it will break. The further the discovery slips into later phases, the more the rework cost is said to balloon by orders of magnitude
- Talent — Engineers versed in both Oracle and SQL Server are extremely hard to secure in the hiring market
- Control — Internal regulations do not permit handing real data and production information to an external AI
The strain on the talent side also shows up in statistics (a Ministry of Economy, Trade and Industry estimate [2019] projects a shortage of about 450,000 IT personnel in 2030 under the medium scenario ([2]); an IPA survey found that 51.7% responded with a shortage of DX talent "quality" ([3])), but the on-the-ground feeling is simpler. While the retirement and transfer of the in-house person who knows Oracle inside out loom, maintenance fees go out rigidly every year. The consideration of migration has become not a matter of "we'll do it someday" but of "who does it while someone still can."
This article is a field verification of how far AI can resolve 1 and 2, while accepting these three — particularly "3. Control" — as a constraint.
2. The Scope of This Article — What We Did, What We Have Not Yet Done #
To avoid exaggeration, let me state the scope first. The migration tool is premised on the use of SSMA (SQL Server Migration Assistant, Microsoft's genuine migration-support tool).
| Phase | Content | As of this article |
|---|---|---|
| (1) Prediction | Creating a compatibility checklist (predicting SSMA's conversion results in advance, in 25 items) | Done |
| (2) Tool measurement | Running an Assessment with SSMA for Oracle | Next |
| (3) Expected values | Creating the conversion result that should be (the T-SQL expected schema) | Done |
| (4) Diff review | Diffing the SSMA output against the expected-value schema | Next |
| (5) Actual-machine verification | Applying the expected schema to the target and a functional smoke test | Done |
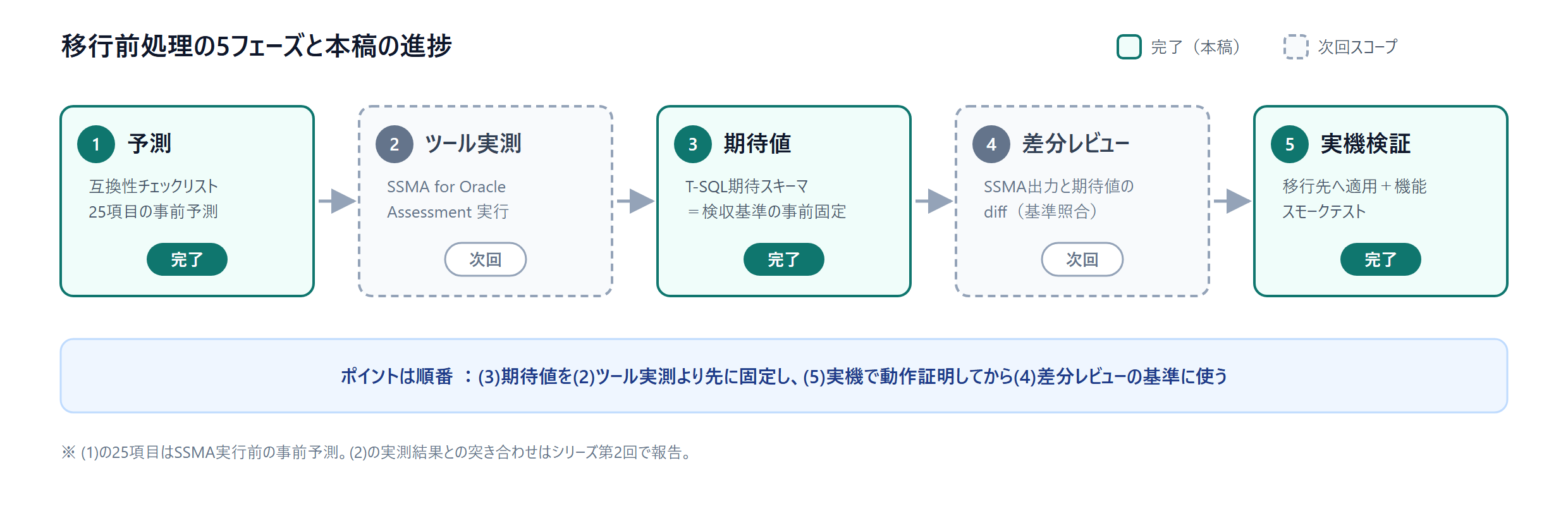
The point is the order. Write (3) expected values before (2) tool measurement, and demonstrate operation through (5) on the actual machine. Expected values proven to work can be used as the "acceptance criteria" for reviewing the tool output. It is a form of bringing the test-driven-development mindset into a migration project. Note that the expected values are written in T-SQL (SQL Server's SQL dialect).
The 25-item checklist is, at this point, merely an advance prediction. The reconciliation with SSMA's actual measurement results — that is, how much the prediction hits and where it misses — will be reported in the next article.
One more thing: let me also make clear the area this article does not cover. A DB migration project as a whole includes the major process of reworking the application-side assets (embedded SQL, the data-access layer, reports, batch jobs, DB-link integration, etc.), which generally accounts for the majority of the total effort. What this article covers is the conversion part of the schema and in-DB logic, which is only a portion of the whole. That said, this is also the foundation work that "must be fixed first, or all subsequent work becomes rework."
3. The Three Control Principles Decided First — Designing "What Not to Hand the AI" #
Before starting the work, we fixed the following three principles.
- Do not handle real data (verification data is entirely fully synthetic)
- Do not persist credentials in code or files
- Do not needlessly expose the target DB's port externally
The line for what information may be handed to the AI is as follows.
| May hand over | Do not hand over |
|---|---|
| DDL (table, constraint, procedure definitions) | Row data (whether production or extracted) |
| Schema structure and type information | Any data whatsoever that includes personal information |
| Error logs and execution-result metadata | The DB's permanent credentials (storing them in files or code is also prohibited) |
| Statistical metadata such as row counts | Details of the internal network configuration |
* The remote connection information for the verification machine was provided temporarily under human management, and the operation is to rotate it after the work (see Chapter 10).
Organizing the Very Act of "Sending to an External AI Service" #
Even if you "do not hand over real data," DDL and error logs are still information assets. When using an external AI service, you need to decide the line after confirming at minimum the following contract conditions.
- That input and output are not used for model training (the Claude Code used in this verification publicly states that, under its commercial-use terms, it does not use input for model training by default. Confirming the latest terms per usage plan is essential)
- The retention period and deletion conditions of the data
- The processing region and governing law
- Additional measures for when the schema itself is confidential. You can take an approach of mechanically anonymizing table and column names before handing them over, and reverse-converting the results in-house (the mapping table is kept in-house only)
Because this principle came first, the subsequent technical decisions were automatically directed. For example, DB authentication was leaned toward OS integrated authentication, adopting a configuration of "not creating the secret information called a password in the first place." As a result, at the point of completion, the DB-connection secret information exists in none of the deliverable files, scripts, or execution logs.
Implication: Rather than placing AI-use guidelines on a shelf as "a list of things you must not do," loading them into the AI first as project rules / a prompt greatly increases their enforcement power. However, in this verification, attempted deviations still occurred twice (Chapter 8). Prior instructions are not complete on their own; control is established only with three layers including the approval gate and the guardrail.
4. What We Handed Over Instead of Real Data — The Composition of the Migration Verification Kit #
Instead of handing over real data, we first had the AI design a "verification Oracle schema with compatibility problems intentionally built in." As a proxy for the production schema, it condenses into a single schema the elements that tend to cause problems in migration.
The verification kit (five deliverables)
| Deliverable | Content |
|---|---|
| ① Source DDL | 10 tables of a fictional business schema for customers, orders, inventory, and so on. Covers SEQUENCE + trigger numbering, PL/SQL procedures, CONNECT BY hierarchical views, ROWNUM paging, materialized views, composite keys, and CHECK constraints |
| ② Synthetic-data generation SQL | Row counts parameterized (by default, tens of thousands to 500,000 rows per table, totaling on the scale of over one million rows) |
| ③ Compatibility checklist | 25 items of advance prediction of SSMA conversion results (Chapter 5) |
| ④ Expected-value schema (T-SQL) | The conversion result that should be. All conversions have a reason comment (Chapter 6) |
| ⑤ Verification scripts | DB creation, application, and row-count reconciliation on the target |
We added a twist to the design of the synthetic data. We designed it so that "values that tend to cause problems" — Japanese, NULL, boundary values, special characters, and emoji — are always injected as "guaranteed rows," not left to randomness. This is to get ahead of problems that occur in production data and reproduce them in synthetic data. Because the random seed is fixed, it is a design that can reproduce the same verification data any number of times (running the generation on the actual Oracle machine is in the next scope; this is intended for reproduction at audit time).
The AI itself, through self-review, detected and fixed three bugs in the generation SQL it created (a non-deterministic join, a length-limit overrun with multibyte characters, and an invalid optimization hint) before execution. It is not that "the AI's deliverables are infallible," but that "it is fast, self-verification loop included" — that is the correct understanding. The AI's output is also a subject of verification — this premise runs through the entire method.
5. Reading the Compatibility Pitfalls by "Business Impact" #
Oracle → SQL Server compatibility problems tend to be discussed in technical jargon, but in a decision-making setting they need to be translated into business impact. From the 25-item checklist, we excerpt the six that are especially dangerous.
All SSMA behavior described in this chapter is advance prediction before execution (reconciliation with actual measurement is next time).
① Non-Unicode conversion of VARCHAR2/CLOB #
- Prediction: The default conversion is expected to turn these into VARCHAR/VARCHAR(MAX). Characters not in the collation's code page (emoji, extended kanji, etc.) garble into "?", and in an environment with a non-Japanese collation, all Japanese garbles
- Business impact: Irreversible data corruption of customer names and addresses. Even if you notice after migration, you cannot restore the original
- Remedy: Specify NVARCHAR/NVARCHAR(MAX) explicitly
② Loss of time in Oracle DATE #
- Prediction: Oracle's DATE retains down to seconds. Mapping it carelessly to SQL Server's DATE type loses the time (we predict SSMA's default is DATETIME2(7), in which case the time is retained but the precision is excessive)
- Business impact: Timestamps of order times and audit trails vanish, breaking closing processes and SLA measurement
- Remedy: Receive it as DATETIME2(0)
③ FLOAT-ification of precision-less NUMBER #
- Prediction: A NUMBER without a precision specification is expected to be converted to a floating-point type, introducing rounding error
- Business impact: Amounts and quantities drift, and accounting reconciliation does not pass
- Remedy: Specify DECIMAL/BIGINT explicitly
④ The difference in handling empty strings and NULL #
- Prediction: In Oracle, an empty string '' is NULL. In SQL Server it is treated as a separate thing (this is a specification difference between the two products and is a settled fact, not a prediction)
- Business impact: No error appears, yet only the judgment result of the business logic changes. The hardest to discover
- Remedy: Decide the normalization policy at migration time in advance
⑤ CONNECT BY hierarchical queries #
- Prediction: Predicted to be non-auto-convertible. Queries for organizational hierarchies, BOM, and account-code trees are the targets
- Business impact: The effort of manual rewriting hits the estimate directly
- Remedy: Rewrite to a recursive CTE (hierarchical querying via a common table expression). An equivalent implementation is prepared
⑥ Materialized views #
- Prediction: There is no fully equivalent feature (an indexed view is maintained automatically, but the constraints are large in terms of refresh specification, the freedom of aggregation, and so on)
- Business impact: Redesigning the foundation of nightly batches and report aggregation
- Remedy: A table + refresh process, or an indexed view if the constraints can be tolerated
The prediction breakdown across all 25 items is: 10 expected to be auto-convertible, 11 warnings requiring review, 2 non-auto-convertible, and 6 requiring human design decisions. The total comes to 29 classifications because some items fall into multiple categories. In other words, at the prediction stage, the cases expected to "be done as is by leaving it to the tool" are about 40% of the whole. How you prepare for the remaining 60% determines the migration quality.
This 25-item checklist is made at a granularity that readers can reuse for their own migration projects as a "review-viewpoint table" or "estimate basis."
6. The Expected-Value Schema — Having the AI Write the Migration's "Acceptance Criteria Document" #
The core of this method is to fix the conversion result that should be (the expected values) first, rather than thinking after seeing SSMA's output. The expected-value schema generated by the AI has a reason comment on every conversion. An excerpt of the type-mapping table is shown.
| Oracle | SQL Server (adopted) | Reason for adoption |
|---|---|---|
| NUMBER (no precision, integer use) | BIGINT | Avoids error from FLOAT-ification |
| NUMBER(p,s) | DECIMAL(p,s) | Maps as is |
| DATE (column that retains time) | DATETIME2(0) | Because the DATE type loses the time |
| DATE (date-only column such as a birthday) | DATE | The business judgment that time is unnecessary |
| VARCHAR2 / CLOB | NVARCHAR / NVARCHAR(MAX) | Avoids garbling of Japanese |
| SEQUENCE + trigger numbering | IDENTITY | Performance and maintainability. A SEQUENCE-retention option is also noted |
| CONNECT BY | Recursive CTE | With an equivalent implementation of hierarchy, path, and leaf detection |
| ROWNUM paging | OFFSET / FETCH | To standard syntax |
| Materialized view | Table + refresh procedure | An indexed view too, depending on requirements |
What I would like you to note is that even for the same DATE type, the judgment is split per column: "the order date-time is DATETIME2(0), the birthday is DATE." This is a business-informed design decision that does not come out of a mechanical bulk conversion. This decision was not written by a human from scratch; the AI proposed it, made the reason explicit in a comment, and a human reviewed and approved it.
Rather than ending with "the AI made it," leave the conversion reasons and the alternatives not adopted as comments in the deliverable. Merely mandating this turns AI deliverables into traceable documents whose decisions a successor or auditor can follow.
7. Demonstrating Operation on the Actual Target Machine — "Converted" and "Works" Are Different #
The expected-value schema does not become acceptance criteria merely by being written. If the criteria themselves do not work, they cannot be a yardstick for measuring the tool output. So we applied it to the actual SQL Server 2022 target machine (collation Japanese_XJIS_140_CI_AS) and carried it through to functional verification.
Application result: 29 batches executed, zero errors (11 tables [10 business tables + 1 materialized-view alternative table] / 3 views / 1 function / 2 procedures. This is the result of the final application after fixing a defect on the application-tool side).
Functional smoke test (demonstrating that the Oracle-specific feature conversions "work"):
| Verification target | Result |
|---|---|
| IDENTITY numbering (replacement for SEQUENCE + trigger) | PASS |
| T-SQL porting of PL/SQL procedures (retrieving numbered values, error handling, transaction control) | PASS |
| Scalar functions including NVL→ISNULL | PASS (the calculation results match the expected values) |
| CONNECT BY→recursive CTE (hierarchy depth, path string, leaf detection, root name) | PASS (all items reproduced accurately) |
| ROWNUM→OFFSET/FETCH paging | PASS |
| Materialized-view alternative (table + refresh procedure) | PASS |
| Automatic aggregation reflection of the indexed view | PASS (even inventory deduction by orders is reflected automatically) |
What I most want to convey is the Unicode verification. When we injected and retrieved the string "絵文字A😀🍣" containing emoji, it was a perfect match at LEN=6 / DATALENGTH=16 bytes. This means we confirmed — not by qualitative evaluation but by numbers — that the "_140"-generation collation correctly treats surrogate pairs (supplementary characters such as emoji) as a single character. In an enterprise that handles Japanese data, only after verifying to this extent can you say "it does not garble."
As a matter of verification etiquette, the functional test is run by creating a disposable scratch DB, which is discarded after it finishes. The main verification DB, which awaits SSMA measurement, is kept clean.
During verification, bugs in the verification scripts the AI itself wrote (such as the splitting process of SQL batches, or errors in the column names of system views) surfaced as actual-machine errors, and there were several scenes where the AI read the error messages and self-corrected. That the unremarkable iteration of "hitting it against the actual machine and fixing it" runs without human hands — this is the description closest to the reality of effort compression.
For fairness, let me also make clear the limits of this verification. The verification schema and the expected values were both designed by the AI, and structurally it is at the stage of "passed a test it made itself." To keep this from ending in self-righteousness, the expected values are designed to be reconciled with the output of an independent converter called SSMA via a diff (next time). Also, this is success at the scale of merely 10 tables; problems that newly appear in a real schema on the scale of hundreds to thousands of objects, involving DB links, partitions, and PL/SQL packages, are unverified.
8. An Unexpected Harvest — The AI's Guardrail Became a "Sentinel of Control" #
What was rich with implications in this verification was an unplanned event. During the work, the safety mechanism (guardrail) on the AI side blocked operations, before execution, twice. Note that the targets were all our own verification environment, not exposed to the internet, and do not include production or customer environments.
- Case ①: When the AI prioritized work efficiency and proposed/attempted an operation in the direction of weakening a security setting (an approach of relaxing a protection mechanism to push the processing through), the safety mechanism rejected it before execution. Rather than looking for a workaround, the AI switched to an alternative means that holds with the safer default setting left as is, and continued
- Case ②: When the AI tried to write credentials to a file and use them, it was rejected before execution. It changed course and, in this verification phase, arrived at an OS-integrated-authentication-based configuration of "not creating the secret information called a password in the first place"
What matters is that both were stops consistent with the three control principles the humans had fixed at the outset. The guardrail functioned not as an impediment to the work but as a "sentinel of the design principles," and pushed the final configuration toward the safer side instead.
However, reading this as "since there is an AI safety mechanism, it's fine" is a mistake. The guardrail's behavior depends on the model and version, and it alone is not a basis for control. The practical model derivable from this verification is three-layer control.
- Layer 1: Prior principles — Fix the line for what information may be handed over and the prohibitions as the first instructions to the AI
- Layer 2: Human approval gate — At moments where a premise collapses, the AI limits itself to presenting options, and the humans decide the policy
- Layer 3: Guardrail — The final breakwater for dangerous operations that slip through Layers 1 and 2
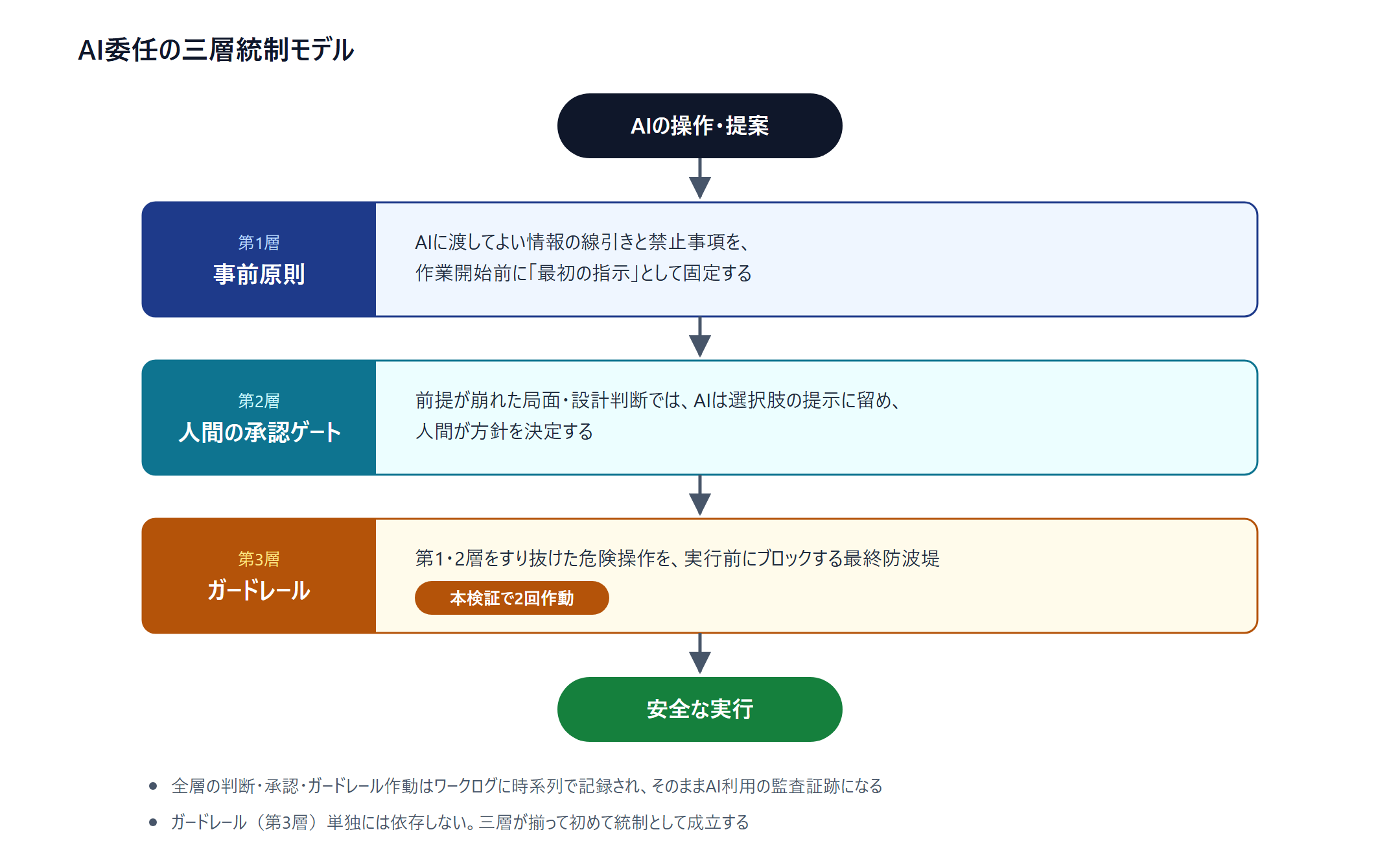
Layer 2 actually functioned in this verification too. In scenes where it turned out that the environment's premise differed from the assumption, the AI did not proceed on its own judgment but presented options, and the humans approved the policy. Design decisions such as selecting the numbering method were the same.
As a premise of control, we also limit the execution environment given to the AI. The target is only a verification-dedicated machine in an internet-non-public segment, with no connection route to production systems. All operations are recorded, and a human can stop the session at any time. Furthermore, we keep on the human side a means of detection in case the guardrail does not activate. Specifically, it is an operation of reviewing the operation records in the work log after the fact from the viewpoint of "operations involving authentication, privileges, and external transmission."
And the work log that records, in chronological order, which judgment the AI made, where the human approved, and where the guardrail activated, doubles as the audit trail of AI use.
9. The Moves Entrusted to the AI, the Judgments Left to Humans #
The track record of the role division through this verification is as follows.
| What the AI replaced (moves) | What remained with humans (judgment) |
|---|---|
| Exhaustively identifying the compatibility points (25 items) | Selecting the numbering method (IDENTITY, or maintaining SEQUENCE semantics) |
| Generating the conversion DDL and expected-value schema | Whether time is needed per column (the distinction between order date-time and birthday) |
| Creating the synthetic data and verification scripts | The specification judgment of whether to absorb the empty-string=NULL difference on the app side |
| Actual-machine application and self-correction from errors | Selecting the collation (the character-encoding strategy) |
| Documentation with reason comments | Approving the change of course when a premise collapsed |
What this line means is a change in the talent profile needed for migration. Rather than searching for a "two-sword engineer who can write both Oracle and SQL Server from scratch," it suffices to have a reviewer who can read and judge the type-mapping table, checklist, and options the AI generated. The latter is far more realistic to both procure and develop.
Let me also touch on the effort. The breakdown of this verification (10-table scale) is as follows.
| Item | Track record / form |
|---|---|
| The AI's work (kit design, conversion, actual-machine application, verification) | A series of work that fits within a single day's work record |
| The humans' work | Policy approval (a few decisions at the approval gates) and deliverable review |
| AI usage fee | Depends on the usage plan (this verification was within the range of a flat-rate plan) |
In our experience to date, this kind of preprocessing has typically required weeks, even after securing personnel versed in both DBs. However, since the requirement depends on the project scale and schema complexity, we refrain from generalizing this comparison as a quantitative effect. When a reader estimates for their own project, placing "number of target objects × review time (the more tables that require type, numbering, and date judgments, the heavier)" as the basis of the human-side effort, and considering the AI-side generation and verification as its dependent variable, should be closest to reality.
Let me also concretize the reviewer requirement of "it suffices to have a reviewer." What is needed is the right column of the role-division table above — that is, being able to make decisions on the numbering method, date types, collation, and NULL policy — and in practice it is enough to have one person with design experience on the SQL Server side. If there is someone in-house with SQL Server operation and design experience, it can be done in-house; if not, using external review just for that judgment part is the realistic branch.
10. A Checklist for Trying It Yourself #
We summarize the key points when applying this method to your own migration consideration.
Drawing the line on information (translating into AI-use guidelines)
- May hand over: DDL, schema structure, error logs, statistical metadata
- Do not hand over: row data, personal information, the DB's permanent credentials
- Connection information temporarily shared out of operational necessity must be provided under human management and always rotated after the work
- When the schema itself is confidential: consider anonymizing table and column names, and extracting structure only
Requirements for synthetic data
- Fully synthetic (no mixing-in of production values)
- A design reproducible with a fixed random seed
- Includes "guaranteed rows" of Japanese, NULL, boundary values, special characters, and emoji
Requirements for deliverables
- A reason comment on every conversion decision (including the alternatives not adopted)
- Separate recording of prediction and measurement (a "prediction" label on the checklist)
- Preservation of the work log (so that the decision-maker can be traced chronologically; sanitize when providing externally)
Requirements for operation
- Advance definition of the judgment points that pass through a human approval gate
- Make the AI's rejection (guardrail activation) events subjects of recording too
11. Conclusion — Migration Quality Goes From "Find It Later" to "Fix It First" #
What was demonstrated
- Migration preprocessing (compatibility prediction, conversion design, application and functional verification on the actual target machine) can be completed without handing the AI a single row of real data
- "Fixing the acceptance criteria in advance" by writing the expected-value schema first and demonstrating operation on the actual machine reaches practical speed with AI
- If you give the control principles to the AI first and layer the approval gate and the guardrail, it functions as a mechanism on the control side
What has not yet been demonstrated
- The results of the actual conversion by SSMA (the 25-item checklist is at the advance-prediction stage)
- The challenges of the real-data migration phase (data quality, performance at scale, operational design). This remains an area to be handled by humans and dedicated tools in a controlled in-house environment
Next time, we will actually measure SSMA for Oracle's Assessment Report and reconcile, one by one, how much of the 25-item prediction hit and where it missed. It is a verification made possible precisely because we fixed the prediction first as a document. The items where the prediction missed should be the most valuable knowledge for the organization.
Appendix A: The Overall Picture of the 25-Item Compatibility Checklist (Advance Prediction of SSMA Conversion Results) #
Legend for the categories: Auto = expected to be auto-converted / Warning = converted but requires review / Error = expected to be non-auto-convertible / Design = requires a human design decision
| # | Item | Predicted category |
|---|---|---|
| 1 | Precision-less NUMBER (integer use) | Warning |
| 2 | NUMBER(p,s) | Auto |
| 3 | NVARCHAR2 | Auto |
| 4 | VARCHAR2 (Japanese storage) | Warning |
| 5 | CLOB | Warning |
| 6 | DATE (use including time) | Warning |
| 7 | TIMESTAMP(6) | Auto |
| 8 | The maximum length of VARCHAR2(4000) (byte length and character length) | Warning |
| 9 | Precision-less NUMBER (with decimals) | Warning |
| 10 | BLOB | Auto |
| 11 | Composite primary keys and composite foreign keys | Auto |
| 12 | CHECK constraints | Auto |
| 13 | NCLOB | Auto |
| 14 | Self-referencing foreign keys | Auto |
| 15 | SEQUENCE objects | AutoDesign |
| 16 | Numbering by a BEFORE INSERT trigger | WarningDesign |
| 17 | PL/SQL functions | AutoWarning |
| 18 | PL/SQL procedures (%TYPE, RETURNING, etc.) | WarningDesign |
| 19 | CONNECT BY hierarchical queries | Error |
| 20 | ROWNUM paging | WarningDesign |
| 21 | Materialized views | ErrorDesign |
| 22 | Empty-string ''=NULL semantics | Warning |
| 23 | Supplementary characters (emoji, 4-byte UTF-8) | WarningDesign |
| 24 | SYSDATE / SYSTIMESTAMP | Auto |
| 25 | The DUAL pseudo-table | Auto |
Appendix B: An Example AI-Use Guideline Clause Set (a Draft for Internal Consideration) #
- (Classification of information) The information that may be provided to the AI shall be schema definitions (DDL), error logs, and statistical metadata. Providing row data, personal information, and permanent credentials is prohibited.
- (Verification data) Data used for AI-assisted verification shall be fully synthetic, and the generation conditions (random seed, etc.) shall be recorded to ensure reproducibility.
- (Approval gate) Design decisions and changes to work premises shall be carried out through the AI's presentation of options and the person in charge's approval.
- (Recording) The AI's operations, judgments, and safety-mechanism activation events shall be recorded chronologically and preserved. Sanitize when providing externally.
- (Temporary credentials) Credentials shared temporarily out of operational necessity shall be invalidated after the work is completed.
Sources #
- [1]: Oracle Lifetime Support Policy: Oracle Technology Products (Oracle official) https://www.oracle.com/us/assets/lifetime-support-technology-069183.pdf (supplementary reporting: The Register, February 2025 https://www.theregister.com/2025/02/18/oracle_extends_19c_support/ ). Confirmation under your own contract is recommended for the offering and exclusions during the extension period.
- [2]: Ministry of Economy, Trade and Industry, "Survey on Supply and Demand of IT Personnel" (2019) https://www.meti.go.jp/policy/it_policy/jinzai/gaiyou.pdf
- [3]: IPA, "DX White Paper 2023." The share of companies that responded that the "quality" of personnel driving DX is significantly lacking was 51.7% in the FY2022 survey (30.5% in FY2021) https://www.ipa.go.jp/publish/wp-dx/gmcbt8000000botk-att/000108046.pdf




