
BESTNET TECH BLOG
AI guardrails and three-layer governance — a field record of being blocked twice during a DB migration
Entrusting an AI coding agent with real work on a server. Letting it convert schemas, build a verification environment, run tests — that kind of usage is becoming realistic. And naturally, this worry arises: "What if the AI does something it must not do?"
In the main installment of this series, we reported a hands-on case where we automated the preprocessing for an Oracle-to-SQL Server migration with an AI agent (Claude Code) without handing over any real data. This article deals with an event that occurred within it and was not in the plan. During the work, the safety mechanism (guardrail) on the AI agent's side blocked the AI's own operation, before execution, twice.
Note that this article explores those two cases from a "governance perspective." The technical behind-the-scenes of the work in which they occurred (the ten pitfalls hit at the seams of SSH non-interactivity, character encoding, and PowerShell/T-SQL) are split out into the technical side note, "Ten Pitfalls Hit When Entrusting an AI Agent With Hands-On Windows Work."
At first glance this looks like a "the AI won't do as it's told" kind of trouble. But in hindsight, it was an event rich with implications for thinking about governance. I will write about it from both sides, as honestly as I can. As a caveat up front, what activated here was the safety judgment built into a particular AI agent implementation; there is no guarantee that the same operation would be stopped by another tool, model, or version (this non-determinism is detailed in Chapter 4).
The work target in this article is our own verification-only environment, which is not exposed to the internet. It does not include any production system or customer environment.
1. Stopped Twice #
The one carrying out the work was the AI agent. The humans (us) had stepped back into the role of approving the policy and reviewing. A move that AI tried to make, prioritizing efficiency, was deflected before execution — both times.
Case 1: An execution method that weakens a security setting #
To investigate the environment, the AI tried to run an investigation script using a method that temporarily weakens the execution policy (the equivalent of -ExecutionPolicy Bypass in PowerShell terms). Even though the purpose was read-only, it is an operation that bypasses a protection mechanism.
Here the guardrail rejected it as a "security-weakening operation." Rather than looking for a workaround, the AI realized that there had been no need to weaken it in the first place. With the target environment's default setting (RemoteSigned) left as is, the script could be executed, and there was no reason to touch the policy. As a result, it switched to a safer method and moved forward.
Case 2: Writing credentials to a file #
In automating the product installation, the AI initially tried to install SQL Server in mixed-mode authentication (the method that uses the sa account), and tried to write that sa password directly into a script file and transfer it.
Here too the guardrail rejected it as a "credential leak." This was an operation that ran squarely against the principle the humans had set before work began: "Do not persist credentials in code or files." The AI changed course, abandoned mixed mode, and switched to a configuration using only Windows integrated authentication (creating neither sa nor its password). As a result, it arrived at a configuration in which no secret information remains anywhere — not in the deliverables, scripts, or logs.
What the two cases have in common is that both stopped before execution, and that after being stopped, they advanced toward a safer configuration.
2. Why It Can Be Called a "Sentinel" #
What deserves attention is that the two blocks matched the principles the humans had fixed at the outset.
Case 2 is the explicit principle itself: "Do not persist credentials." Case 1 was also the line of "Do not needlessly weaken protection mechanisms" — a premise we held even without bothering to write it down.
In other words, the guardrail worked not as an obstacle hindering the work, but as a "sentinel" of the design principles the humans had decided. And it did not merely stop things; being stopped became the trigger for the configuration to tip toward the safer side. We ended up arriving at a more robust design we had not initially chosen — one of "not creating secret information in the first place."
3. Another Reading — The Same Event Is Evidence That "the AI Made a Risky Proposal" #
If we stop here, this becomes an article praising AI guardrails. Let me honestly flip it over.
Being blocked twice means that, even though the principles had been loaded in at the start, the AI still attempted operations that violated the principles twice.
This should be understood not as an isolated configuration mistake, but as a property inherent to AI delegation at the present moment. An AI agent (regardless of the model) can propose moves that violate principles, prioritizing efficiency. That is precisely why we draw the line at Layer 1 (prior principles) and prepare for what slips through at Layer 3 (the guardrail) — and this time, as designed, the attempted deviations were detected before execution. That said, without the guardrail, or if the judgment differed on another model or version, those operations might have been executed as is.
Looking at only one side of this duality leads to a wrong judgment.
- Looking only at the optimistic side: "Since there's a safety mechanism, it's fine to leave it to the AI" → you become defenseless against what the guardrail misses
- Looking only at the pessimistic side: "The AI attempts dangerous operations, it's useless" → you let go of a tool that is useful if properly fenced in
The mature view is to hold both at the same time. The AI can propose risky moves, prioritizing efficiency. So a fence is needed. As the last layer of that fence, the guardrail is effective — but you cannot depend on it alone.
4. That's Why You Can't "Depend on It Alone" — the Judgment Depends on the Model #
What is decisive is that the guardrail's judgment is non-deterministic and depends on the model and version. An operation blocked this time might pass under a different setting or version. Conversely, a non-dangerous operation may be stopped excessively.
It is an obvious principle in the world of security — you must not entrust control to a single defensive layer. The guardrail is "a reassuring last line of defense to have," not a "foundation that makes everything else unnecessary because it exists."
So what do you depend on? What we could derive from this hands-on case was a three-layer structure that places the guardrail at Layer 3.
5. Three-Layer Control — the Guardrail Is the Last Line of Defense, Not the Foundation #
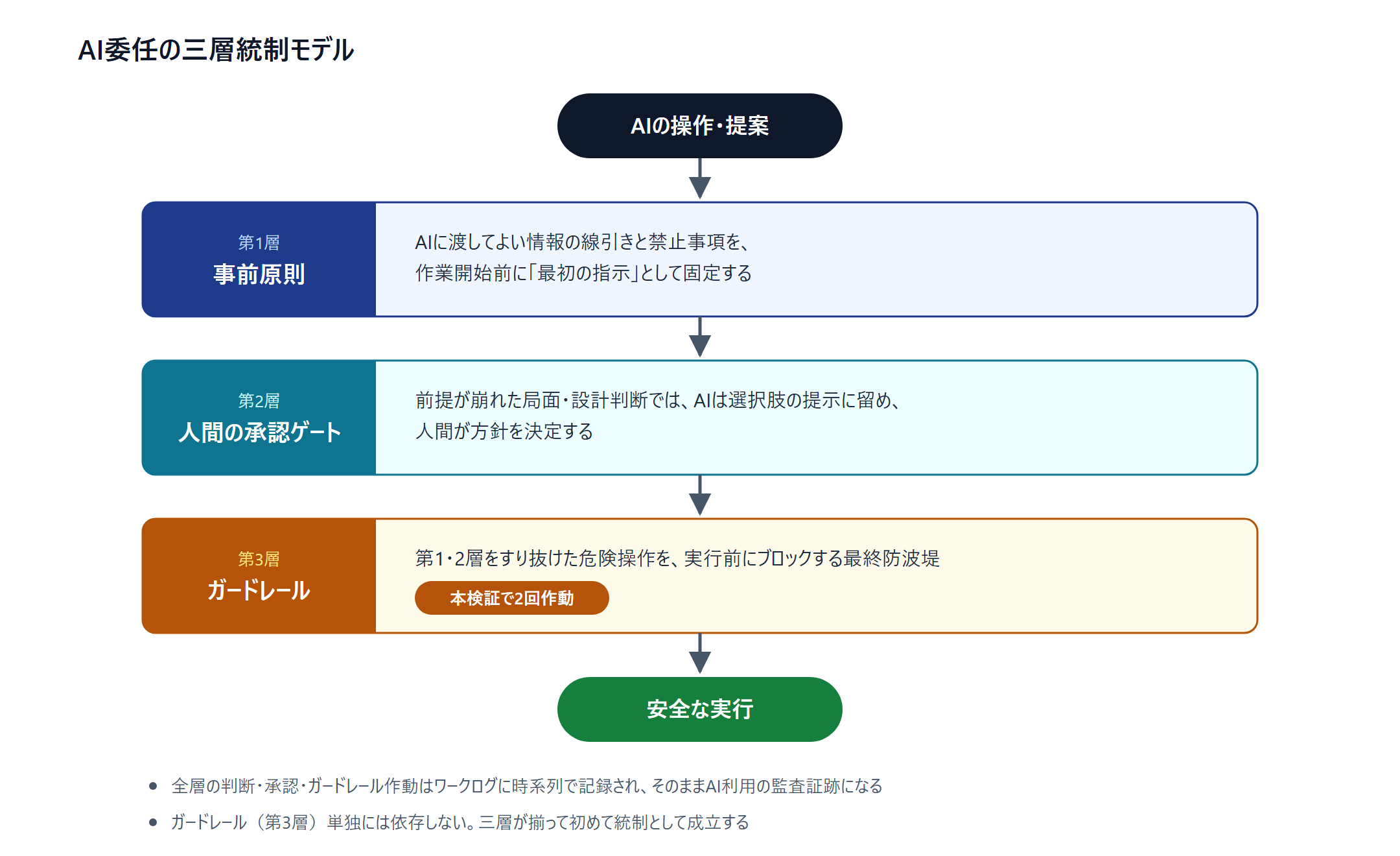
- Layer 1: Prior principles — Fix "information you may hand over / information you do not," "operations you may do / operations you must not do" as the first instructions to the AI before work begins. The "do not persist credentials" of this case belongs here. The foundation of control is not the vendor's safety mechanism, but the line you yourselves drew first.
- Layer 2: Human approval gate — At moments where a premise has collapsed or a design decision is required, the AI limits itself to presenting options, and the humans decide. This time too, when the environment diverged from the initial assumption, the AI laid out options and the humans approved the policy.
- Layer 3: Guardrail — The last line of defense that stops, before execution, dangerous operations that slipped through Layers 1 and 2. This time, it activated twice.
The order matters. If you have designed Layers 1 and 2 yourselves, Layer 3 functions as "insurance." Conversely, if you rely on Layer 3 alone, the moment it comes off, nothing remains.
6. The Hardest Part Is "When the Guardrail Did Not Activate" #
It is easy to say "do not depend on Layer 3," but the crux in practice is here. When it stops you, it is easy to understand. The problem is how you notice when it did not stop you.
In this work, we recorded all of the AI's operations, judgments, and activations of the safety mechanism in a work log in chronological order. This log doubles as the audit trail for AI use. The granularity image is something like "[time] [operation type: execute / approve / block] [target: execution policy change] [result: rejected by the guardrail]" — which is enough to be scanned later per viewpoint. The point is not to "gaze at" the log, but to fix the viewpoints and review it after the fact. At minimum, I believe humans should check the following three viewpoints.
- Authentication: Were there any operations involving the generation, storage, or handoff of credentials?
- Privileges: Did it touch privilege escalation or changes to protection mechanisms (execution policy, firewall, access control)?
- External transmission: Were there any operations sending data to an unexpected destination?
If there is an operation in the log that falls under any of the three viewpoints, the humans must always confirm whether its execution result violates the principles, and if it deviates, carry it through to correction and recurrence prevention (adding to the principles). The guardrail is completed as control only when paired with this system of "humans detecting and dealing with it after the fact." If you are going to entrust work to an AI, the premise is to simultaneously prepare a mechanism for not leaving it entirely unattended — namely, recording and a viewpoint-defined post-hoc review.
7. Translating This Into an AI-Use Policy (AI Governance) #
If we put everything so far into our own AI-use guidelines, the key is not merely to enumerate principles, but to decide "where to put them, and who looks at them, when."
- Placement: Do not put the Layer 1 prior principles on a document shelf; paste them at the start of the work as the AI's "first system prompt / project rules." Guidelines for stocktaking and rules that take effect at execution time are different things
- Approval gate: Define in advance the moments where, for design decisions and premise changes, the AI limits itself to presenting options and the humans approve
- Recording: Make the AI's operations, judgments, and the activation / non-activation of the safety mechanism subjects of recording
- Reviewer and frequency: At the end of each work session, one person not in charge checks the work log against the three viewpoints of "authentication, privileges, external transmission," and records whether any applicable operations existed
- Isolation and least privilege: Cut off the work environment's route to production and customer systems, and keep the privileges granted to the AI minimal
- Premise of non-determinism: Design on the premise that the guardrail's behavior can change with the model/version (do not depend on it alone)
An "example AI-use guideline clause set" written in the style of articles of regulation is provided as a five-item template in Appendix B of the main installment. This article is positioned to add, to that, Chapter 6's "post-hoc review for noticing even when the sentinel comes off."
Conclusion #
The two times the AI agent told its own operation "no" are, on their own, an episode of "a convenient safety mechanism worked." But what matters is that the safety mechanism carried meaning because it matched the line the humans drew first, and that that line must be drawn by yourselves.
The guardrail can become a sentinel. But only when there is an employer (the prior principles) and a patrol mechanism (recording and post-hoc review). Control in the age of entrusting work to AI is neither "trust the clever AI" nor "don't use it because it's dangerous" but rather design the fence in three layers, and make sure you can notice even when the last line of defense comes off — that is the whole of it, this hands-on case taught us.




