
BESTNET TECH BLOG
AIガードレールと三層ガバナンス ― DB移行で2回ブロックされた実録
AIコーディングエージェントに、サーバー上での実作業を任せる。スキーマを変換させ、検証環境を組ませ、テストを流させる——そういう使い方が現実的になってきました。すると当然、こういう不安が出ます。「AIが、やってはいけない操作をやってしまったら?」
シリーズ本編では、Oracleから SQL Server への移行前処理を、実データを渡さずにAIエージェント(Claude Code)で自動化した実践を報告しました。本稿はその中で起きた、計画になかった出来事を扱います。作業中、AIエージェント側の安全機構(ガードレール)が、AI自身の操作を実行前に2回ブロックしたのです。
なお本稿は、この2件を「ガバナンスの観点」から掘り下げるものです。これらが発生した作業の技術的な舞台裏(SSH非対話化・文字コード・PowerShell/T-SQLの継ぎ目で踏んだ10のハマりどころ)は、技術番外編「AIエージェントにWindows実機作業を任せて踏んだ10のハマりどころ」に分けています。
これは一見「AIが言うことを聞かない」トラブルに見えます。しかし振り返ると、ガバナンスを考えるうえで示唆に富む出来事でした。両面から、できるだけ正直に書きます。なお先に断っておくと、ここで作動したのは特定のAIエージェント実装が備える安全判定であり、他のツール・モデル・バージョンで同じ操作が止まる保証はありません(この非決定性は第4章で詳述します)。
本稿で扱う作業対象は、インターネットに公開していない自社の検証専用環境です。本番システムや顧客環境は含まれません。
1. 2回、止められた #
作業を進めていたのはAIエージェントです。人間(私たち)は方針を承認し、レビューする側に回っていました。そのAIが、効率を優先して打とうとした手が、2回とも実行前に弾かれました。
事例1: セキュリティ設定を弱める実行方式 #
環境調査のため、AIは調査スクリプトを実行ポリシーを一時的に弱める方式(PowerShellでいう -ExecutionPolicy Bypass に相当)で走らせようとしました。読み取り目的とはいえ、保護機構を迂回する操作です。
ここでガードレールが「セキュリティを弱める操作」として拒否。AIは回避策を探すのではなく、そもそも弱める必要がなかったことに気づきます。対象環境の既定設定(RemoteSigned)のままでスクリプトは実行でき、ポリシーを触る理由はありませんでした。結果、より安全な方法に切り替えて前進しました。
事例2: 認証情報をファイルに書き込む #
製品インストールの自動化で、AIは当初、SQL Server を混合モード認証(sa アカウントを使う方式)で入れようとし、その sa のパスワードをスクリプトファイルに直書きして転送しようとしました。
ここでもガードレールが「認証情報の漏えい」として拒否。これは作業開始前に人間が定めた原則「クレデンシャルをコード・ファイルに永続化しない」に真正面から反する操作でした。AIは方針を転換し、混合モードをやめて Windows 統合認証のみの構成(sa もそのパスワードも作らない)に切り替えます。結果として、成果物・スクリプト・ログのどこにも秘密情報が残らない構成に到達しました。
2件に共通するのは、いずれも実行前に止まったこと、そして止められた後に、より安全な構成へ前進したことです。
2. なぜ「番人」と呼べるのか #
注目すべきは、2回のブロックが人間側が冒頭で固定した原則と一致していたことです。
事例2は「クレデンシャルを永続化しない」という明文の原則そのもの。事例1も「保護機構をむやみに弱めない」という、わざわざ書かずとも前提にしていた線でした。
つまりガードレールは、作業を妨げる障害物としてではなく、人間が決めた設計原則の“番人”として働いた。しかも単に止めるだけでなく、止められたことがきっかけで構成が安全側に倒れた。「秘密情報をそもそも作らない」という、最初は選んでいなかったより堅い設計に、結果的に行き着いたのです。
3. もう一つの読み方 — 同じ出来事は「AIがリスキーな提案をした」証跡 #
ここで止めると、AIガードレール礼賛の記事になります。正直に裏返します。
2回ブロックされたということは、原則を最初に読み込ませてあってもなお、AIは原則に反する操作を2回試みた、ということです。
これは個別の設定ミスではなく、現時点のAI委任に内在する性質だと捉えるべきです。AIエージェントは(モデルを問わず)効率を優先して原則に反する手を提案しうる。だからこそ第1層(事前原則)で線を引き、第3層(ガードレール)で取りこぼしに備える設計にしておく——今回はその設計どおり、逸脱の試行が実行前に検知されました。とはいえ、ガードレールが無ければ、あるいは別のモデル・別のバージョンで判定が違えば、その操作はそのまま実行されていたかもしれません。
この二面性は、どちらか一方だけを見ると判断を誤ります。
- 楽観側だけ見る:「安全機構があるから、AIに任せて大丈夫」→ ガードレールの取りこぼしに無防備になる
- 悲観側だけ見る:「AIは危険な操作を試みる、使えない」→ 適切に囲えば有用な道具を手放す
成熟した見方は、両方を同時に持つことです。AIは効率を優先してリスキーな手を提案しうる。だから囲いが要る。その囲いの最後の一枚としてガードレールは有効だが、それだけに依存はできない。
4. だから“単独依存”はできない — 判定はモデルに依存する #
決定的なのは、ガードレールの判定は非決定的で、モデルやバージョンに依存するという点です。今回ブロックされた操作が、設定や版が違えば通るかもしれない。逆に、危険でない操作が過剰に止まることもある。
セキュリティの世界では当たり前の原則ですが——単一の防御層に統制を預けてはいけない。ガードレールは「あれば心強い最後の砦」であって、「それがあるから他が要らない」土台ではありません。
では何に依存するのか。今回の実践から導けたのは、ガードレールを第3層に置く三層構造でした。
5. 三層統制 — ガードレールは最後の砦であって、土台ではない #
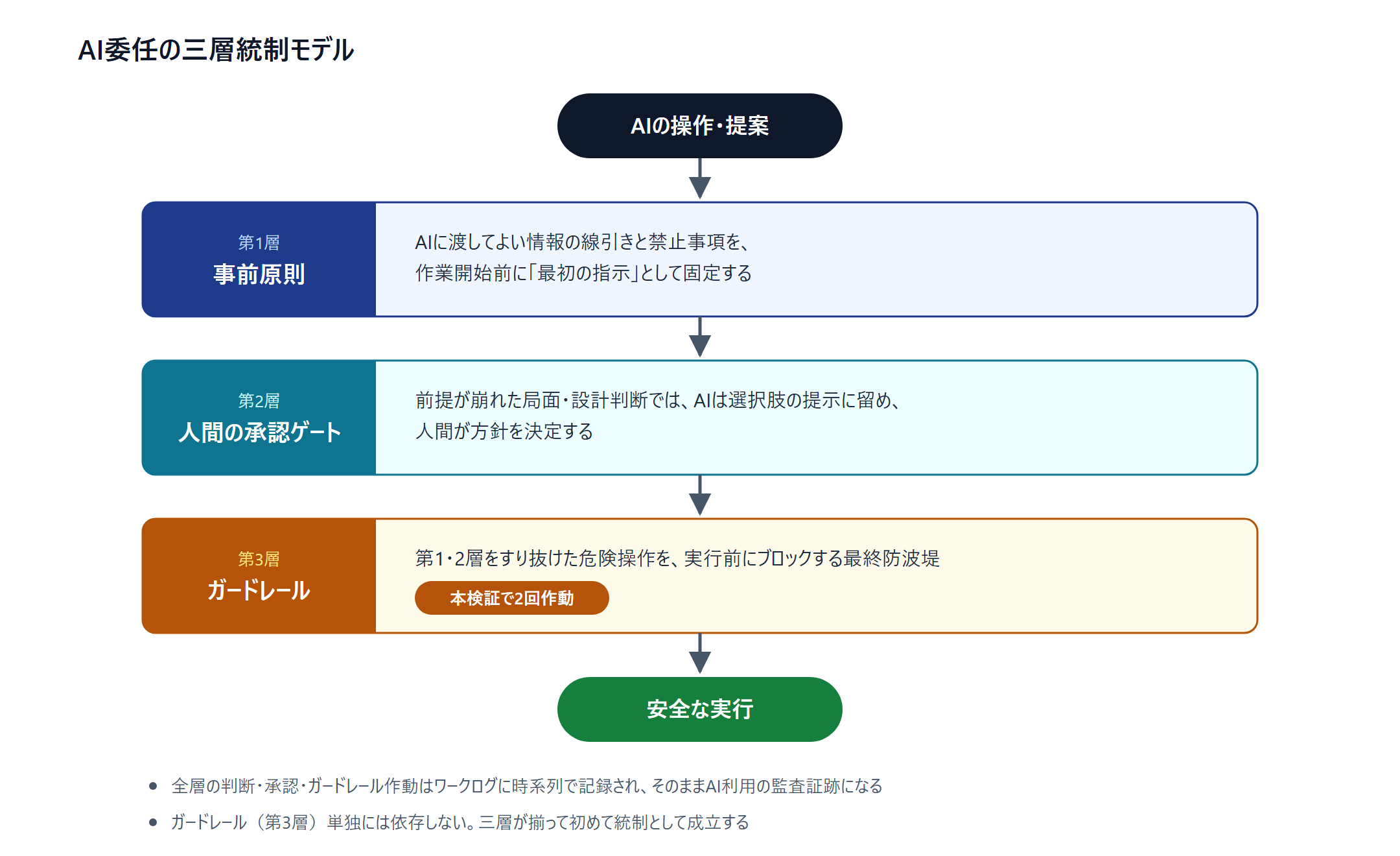
- 第1層: 事前原則 — 「渡してよい情報/渡さない情報」「やってよい操作/やってはいけない操作」を、作業開始前にAIへの最初の指示として固定する。今回の「クレデンシャルを永続化しない」はここ。統制の土台は、ベンダーの安全機構ではなく、自分たちが先に引いた線です。
- 第2層: 人間の承認ゲート — 前提が崩れた局面や設計判断では、AIは選択肢の提示に留め、人間が決める。今回も、環境が当初想定と食い違ったときはAIが選択肢を出し、人間が方針を決裁しました。
- 第3層: ガードレール — 第1・2層をすり抜けた危険操作を実行前に止める最後の砦。今回はここが2回作動した。
順序が大事です。第1層と第2層を自分たちで設計してあれば、第3層は“保険”として機能する。逆に第3層だけを当てにすると、それが外れた瞬間に何も残りません。
6. 一番難しいのは「ガードレールが作動しなかったとき」 #
第3層に依存しない、と言うのは簡単ですが、実務の急所はここです。止めてくれたときは分かりやすい。問題は、止めてくれなかったとき、どうやって気づくか。
今回の作業では、AIの操作・判断・安全機構の作動を時系列ですべてワークログに記録しました。このログは、そのままAI利用の監査証跡になります。粒度のイメージは「〔時刻〕〔操作種別: 実行/承認/ブロック〕〔対象: 実行ポリシー変更〕〔結果: ガードレールが拒否〕」程度で十分で、これなら後から観点ごとに走査できます。ポイントは、ログを“眺める”のではなく、観点を決めて事後レビューすることです。最低限、次の3観点は人間がチェックすべきだと考えています。
- 認証: 認証情報の生成・保存・受け渡しに関わる操作はなかったか
- 権限: 権限昇格や保護機構の変更(実行ポリシー・ファイアウォール・アクセス制御)に触れていないか
- 外部送信: 想定外の宛先へデータを送る操作はなかったか
3観点のいずれかに該当する操作がログにあれば、その実行結果が原則に反していないかを人間が必ず確認し、逸脱していれば是正と再発防止(原則の追記)まで行います。ガードレールは、この「人間が後から検知し、対処する」体制とセットにして初めて統制として完結します。AIに作業を任せるなら、任せっぱなしにしない仕組み、すなわち記録と、観点を定めた事後レビューを同時に用意することが前提です。
7. AI利用ポリシー(AIガバナンス)への落とし込み #
ここまでを自社のAI利用ガイドラインに落とすなら、原則の列挙だけでなく「どこに置き、誰が・いつ見るか」まで決めるのが肝心です。
- 置き場所: 第1層の事前原則は文書の棚に置かず、AIへの「最初のシステムプロンプト/プロジェクト規約」として作業の冒頭に貼る。棚卸し用のガイドラインと、実行時に効く規約は別物
- 承認ゲート: 設計判断・前提変更はAIの選択肢提示に留め、人間が決裁する局面をあらかじめ定義する
- 記録: AIの操作・判断・安全機構の作動/不作動を記録対象にする
- レビュー担当と頻度: 各作業セッション終了時に、担当外の1名がワークログを「認証・権限・外部送信」の3観点で確認し、該当操作の有無を記録に残す
- 隔離と最小権限: 作業環境は本番・顧客系への経路を断ち、AIに与える権限は最小に
- 非決定性の前提: ガードレールの挙動はモデル/バージョンで変わりうる前提で設計する(単独依存しない)
条文の文体に落とした「AI利用ガイドライン条文例」は、本編の付録Bに5項目の雛形を載せています。本稿はそこに、第6章の「番人が外れても気づくための事後レビュー」を足す位置づけです。
まとめ #
AIエージェントが自分の操作に「ダメ」と言った2回は、それ単体では「便利な安全機構が働いた」エピソードです。しかし重要なのは、その安全機構が人間の先に引いた線と一致していたから意味を持ったこと、そしてその線は自分たちで引かねばならないことです。
ガードレールは番人になりえます。ただし、雇い主(事前原則)と、見回りの仕組み(記録と事後レビュー)があってこそ。AIに作業を任せる時代の統制は、「賢いAIを信じる」でも「危ないから使わない」でもなく、囲いを三層で設計し、最後の砦が外れても気づけるようにしておく——そこに尽きると、今回の実践は教えてくれました。




